
Building a Large-Scale ERP: Lessons from Facebook, LinkedIn, and Instagram
To design a robust ERP system that can scale to millions of users across regions and evolve over years, it helps to study how leading platforms handle massive concurrent usage and data. This report distills strategies from Facebook, LinkedIn, and Instagram – focusing on infrastructure, data management, high availability, load balancing, concurrency control, security, messaging, and practical design guidance. The goal is a Python-based ERP architecture (suitable for hybrid cloud/on-prem deployment) that achieves high performance, consistency, and availability at scale.
1. Infrastructure and System Architecture
Hybrid Cloud vs. On-Premise: Large platforms often leverage both cloud and private data centers for scalability and control. Instagram, for example, initially ran on AWS but later migrated to Facebook’s own data centers to reduce latency and integrate with Facebook’s infrastructure[1]. This hybrid approach can benefit an ERP: cloud resources provide elasticity for global reach, while on-premises servers handle sensitive data or legacy integrations. The infrastructure should be containerized and orchestrated (e.g. via Kubernetes) to deploy seamlessly across cloud and on-prem environments.
Server Roles and Tiers: A scalable system is typically divided into tiers of specialized servers: web/application servers, background workers, database servers, file storage, and caching nodes. In Instagram’s backend (a large Django Python app), stateless web servers (running Django) handle requests behind an Nginx load balancer[1]
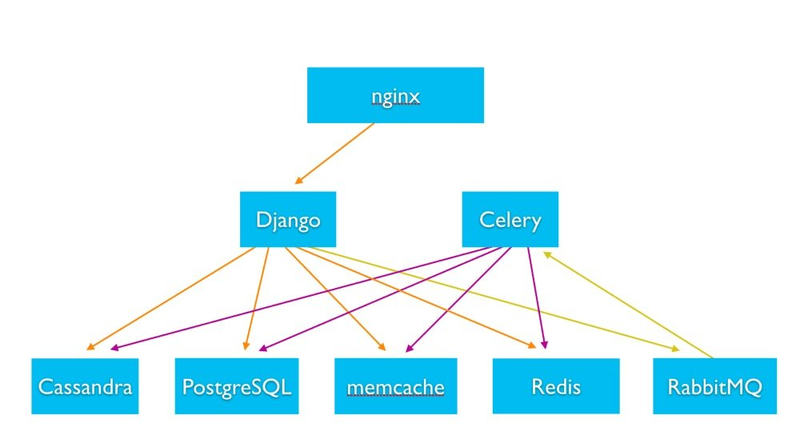
. Separate asynchronous worker servers (Celery workers) handle background jobs[1]. Data is managed by dedicated storage layers – relational databases, NoSQL datastores, in-memory caches, and file/object storage. For instance, Instagram uses PostgreSQL as the primary relational DB, Cassandra (NoSQL) for distributed storage, Memcache and Redis for caching, and RabbitMQ for messaging[1]. Each type of server is optimized for its role (e.g. DB servers with fast disks, cache servers with high RAM).
Instagram’s simplified architecture: stateless Python web servers (Django) and task workers (Celery) interact with diverse backend systems (SQL, NoSQL, cache, messaging)[1][1]. This separation of concerns allows independent scaling of each component (add more web servers for concurrent users, add DB replicas or cache nodes for data access) and easier maintenance.
Microservices vs. Monolith: As user bases grew, both Facebook and LinkedIn evolved from monolithic architectures into microservice-oriented architectures for better modularity and scalability. LinkedIn began as a single monolith (“Leo”) but was later broken into many stateless services (“Kill Leo” initiative) to improve reliability and development speed[2][2]. Each microservice focuses on a specific domain (profiles, search, messaging, etc.), and communicates with others via defined APIs. Facebook similarly operates a “loosely coupled” architecture where features like photos, messaging, news feed, etc. are separate services, often with their own databases[3]. A microservice approach in an ERP can partition modules (finance, HR, sales) into services that scale independently and be developed/deployed in parallel. Services communicate through REST/HTTP or RPC frameworks. (LinkedIn introduced Rest.li for uniform RESTful APIs across teams[2], whereas Facebook built Thrift for cross-language RPC[4].)
Stateless Scaling: Statelessness is key for horizontal scaling. Services should avoid storing session-specific data in memory so that any instance can handle any request. Both LinkedIn and Instagram emphasize stateless web tiers – any server instance can serve any user behind a load balancer[2][1]. User state (sessions, caches) is kept in shared stores (databases, Redis, etc.) rather than local memory. This way, scaling out simply means adding more instances behind the load balancer, without complex session affinity. Stateless design also simplifies failure recovery: if one server dies, the next one can pick up requests with no session loss.
Communication and Integration: In a distributed system with numerous servers and services, clear internal communication patterns are vital. Many large platforms use asynchronous messaging or service discovery systems to connect components. For example, LinkedIn’s services use a discovery and load-balancing layer (D2) to route requests to service instances[2], and Facebook’s services communicate via Thrift RPC, enabling modules written in different languages (C++, PHP, Erlang, etc.) to interoperate[4]. For a Python-based ERP, one might use RESTful APIs (e.g. Flask/FastAPI endpoints) or gRPC for internal service calls. Asynchronous messaging (message queues or event buses) decouples components – more on this in the Notifications section.
Example – Multi-Tier Architecture: A typical large-scale architecture includes multiple layers of services and caches. LinkedIn’s evolved architecture (circa 2015) had frontend web apps, a mid-tier service layer (business logic APIs), and backend data services which interface with databases[2][2]. Caching is applied at various levels: in-memory caches like Memcached or Couchbase were used to reduce load on databases[2], and eventually LinkedIn moved toward keeping caches “closest to the data” (caching at the data access layer) for simplicity[2]. Systems like Voldemort (a key-value store open-sourced by LinkedIn) and Kafka (for streaming data) were integrated for high-throughput data access and transport[2][2]. The diagram below illustrates a multi-tier service architecture with frontends, mid-tier services, and backend data services using databases and caches.
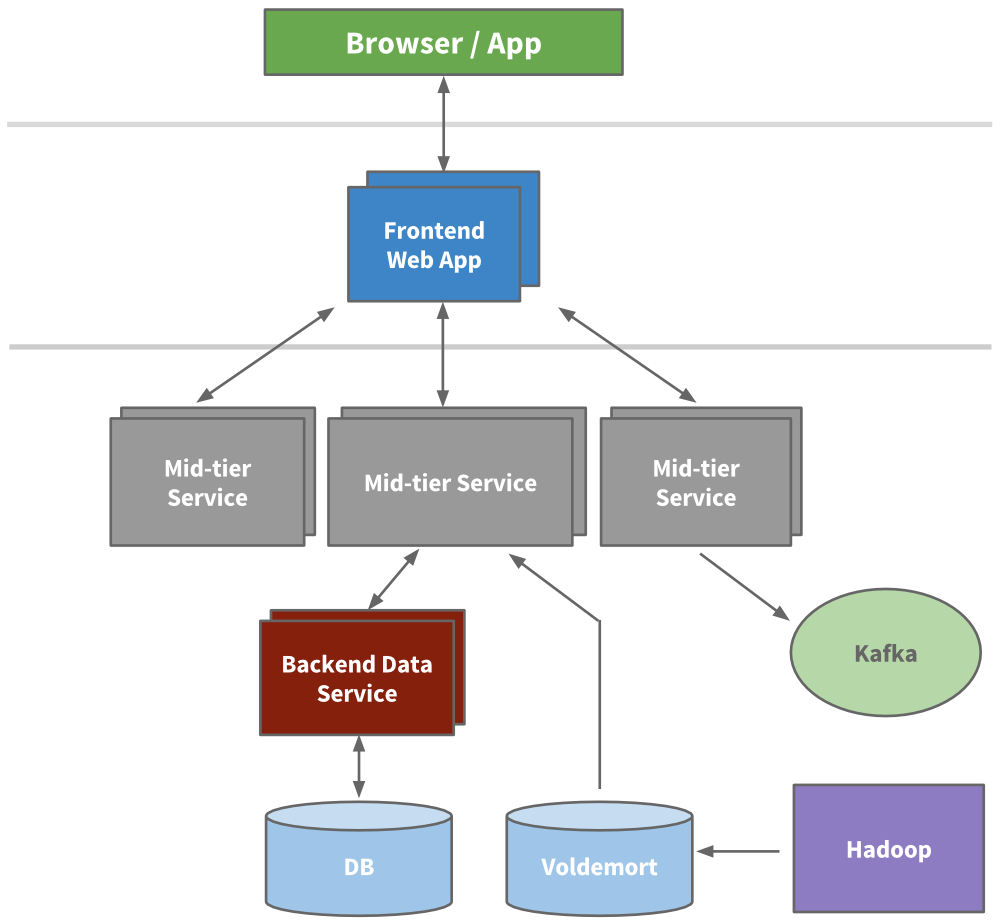
Illustrative multi-tier architecture (inspired by LinkedIn): client requests hit a frontend web server, which calls multiple mid-tier services. Those in turn fetch from backend data services (each with its own database or store). Distributed caches (e.g. Voldemort) and a messaging pipeline (Kafka) help handle read load and data propagation[2][2]. Such layering isolates concerns and allows each tier to scale horizontally.
Infrastructure Summary: The infrastructure for a massive ERP should use clustered deployment across multiple regions, with each service tier scaled out. Employ stateless designs for web/app servers, use specialized servers for databases, caches, and async tasks, and connect them with reliable networks or service mesh. This modular scaling approach, used by companies like Facebook/LinkedIn, ensures the system can handle growth by simply adding capacity at the needed layer.
2. Database Systems and Strategies
Polyglot Persistence: No single database technology suits all needs at large scale. Facebook’s platform is a prime example of polyglot persistence – using different data stores for different types of data[3][3]. MySQL (relational) is Facebook’s primary store for core social data (with a custom RocksDB storage engine for efficiency)[3]. Memcached is layered in front of MySQL to cache results and reduce read load[3]. For large-scale analytics and logging, Facebook turns to Hadoop/Hive data warehouse and HBase (bigtable-style NoSQL) to manage petabytes of data[3][3]. Certain features use specialized stores: e.g. Cassandra (a NoSQL wide-column store) was originally developed at Facebook for inbox search and is inherently distributed and fault-tolerant[3][3]. Time-series monitoring data is handled by custom stores like Gorilla or Beringei[3]. This mix-and-match approach allows each sub-system to use the optimal data model (SQL for structured transactions, NoSQL for high write throughput or flexible schema, in-memory cache for speed, etc.). An ERP can adopt a similar strategy: use an RDBMS (PostgreSQL/MySQL) for financial transactions requiring ACID consistency, a NoSQL or search engine for flexible querying (e.g. full-text search of records), and data warehouse for archival and analytics.
Relational Core with Sharding: Instagram’s backend demonstrates how a traditional relational DB can scale with careful sharding and replication. Instagram uses PostgreSQL as the primary database, storing user profiles, posts, tags, etc.[1]. As data volume grew to billions of records, they evaluated NoSQL alternatives but ultimately sharded the PostgreSQL database to scale horizontally[1]. Sharding means splitting the data into chunks across multiple database servers (for example, dividing users or accounts into multiple DB instances). Instagram’s main DB cluster is spread across 12 high-memory replicas in different zones[1] – providing both read scalability and redundancy. Each shard handles a subset of users, reducing load per DB. They also implemented logical sharding: data is partitioned into many logical shards (e.g. by user ID hash) which are mapped onto a smaller number of physical DB servers. This allows moving logical shards between servers as capacity needs change, without app-level disruption[5][5]. Instagram leveraged Postgres schemas to represent logical shards, and each shard’s tables have their own ID sequences – which simplifies unique ID generation per shard and avoids cross-shard PK collisions[5][5]. For a global ERP, a similar sharding strategy could partition data by region, customer, or functional domain (e.g. separate shards for different business units), all accessed through a unified data access layer.
Schema Design for Scale: Schema design must balance normalization (to maintain consistency) with denormalization (to avoid expensive joins at runtime). Large web platforms often keep highly relational data normalized in the primary store, but use denormalized replicas or secondary indexes for read-heavy features. For example, Instagram’s search infrastructure keeps denormalized documents for users, hashtags, locations optimized for search queries, separate from the normalized core data[1]. These documents (stored in Unicorn search engine, migrated from Elasticsearch) allow fast set-based queries over the social graph[1]. In an ERP, core financial data might stay normalized in an SQL DB (ensuring accuracy), whereas reporting data could be periodically denormalized into a data mart for fast querying. Indexing and partitioning are also crucial: add indexes for frequent query fields but beware of write overhead; partition large tables by date or tenant to improve manageability.
Sharding and Unified Access: When using multiple databases or shards, the application should hide this complexity behind a data access layer or service. Facebook’s TAO system is an example of an abstraction: it presents a unified graph API while fetching from many MySQL shards and cache servers under the hood[6]. Similarly, LinkedIn’s Espresso is a distributed data store that provides a unified query interface but can operate with multi-master replication across data centers[2]. In practice, a directory service or routing function (often based on hashing a key or looking up a partition map) sends each query to the correct shard. The ERP’s data layer might maintain a mapping of, say, “customer 1001 is on DB shard 3” so that application code doesn’t need to know the shard details. Ensuring transparent sharding means adding capacity or splitting shards can happen without major application changes – the routing map is updated, and new servers take on part of the load.
Global Data Consistency: A multi-region deployment introduces the challenge of keeping data consistent worldwide. The CAP theorem dictates we often trade off consistency for availability in distributed systems. Facebook mostly uses a leader-follower (master-slave) replication for its relational data: writes go to a primary, and propagate to replicas asynchronously. This yields eventual consistency across regions. A known effect is that if a value is updated in, say, an Asian data center, a user reading from a U.S. cache may briefly see the old value until caches/databases sync[3]. Facebook tolerates this inconsistency to ensure the site stays highly available and performant, using caching to absorb most reads[3]. On the other hand, LinkedIn’s Espresso data store supports multi-master replication with conflict handling, to allow local writes in multiple data centers[2]. Multi-master systems use techniques like version vectors or timestamp reconciliation to resolve concurrent updates, or they designate certain partitions to particular masters (often pinning each user’s data to a “home” region to avoid conflicts)[2]. For an ERP handling financial transactions, strong consistency is paramount – a common approach is to route all writes for a given record to a single master node (to serialize transactions). Read-only replicas in other regions can serve queries for latency, but writes might be forwarded to the master region or use distributed transactions. Modern NewSQL databases (e.g. Google Spanner, CockroachDB) provide globally-consistent transactions using consensus protocols, albeit with more complexity. Depending on requirements, the ERP might choose an eventual consistency model for certain non-critical data (with background reconciliation) and strong consistency for critical financial data.
Archival and Cold Data: As years pass, an ERP will accumulate massive historical data (orders, invoices, logs). Storing all of it in the main production database can bloat storage and slow down queries (due to large index sizes, etc.). A common strategy is to archive cold data to a data warehouse or long-term storage, keeping the operational database lean. Instagram, for instance, uses Apache Hive (on Hadoop) for data archiving[1]. A scheduled batch job moves older data from PostgreSQL into Hive tables, where it can still be queried for analytics but no longer impacts transactional performance[1]. Archival can be based on data age or relevance – e.g. close fiscal years could be offloaded from the live ERP DB into an archive store or S3 buckets, etc., and retrieved on-demand. The impact on performance is positive: smaller active tables mean faster queries and easier indexing. However, the application needs to be aware if some queries require pulling from archives (or provide a separate reporting interface for historical data). Another aspect of archiving is log and event data – big platforms often stream logs to warehouses in real-time (Facebook’s Wormhole pipeline delivers streaming updates to Hadoop/Hive instead of periodic dumps[7][7]). An ERP can employ a similar event streaming to archive every transaction in near real-time to a backup store, improving reliability and offloading analytic workloads from the primary DB.
Summary of DB Strategies: In practice, a scalable ERP will likely use a primary SQL database cluster (sharded or partitioned by region/tenant), augmented with caches (to offload reads) and possibly NoSQL components for specific use cases (e.g. a document store for attachments or a graph DB for complex relationships). Plan the data model to allow sharding (avoid hard cross-shard joins or use an aggregator service to merge data from multiple shards when necessary). Implement replication and backups for all data stores, and automate failover for resilience. By following the patterns of big platforms – using the right database for each job and designing with distribution in mind – the ERP can manage growth from thousands to millions of users.
3. High Availability and Data Integrity
Downtime and data loss can be catastrophic for large systems. High availability (HA) means the system is resilient to failures (server crashes, data center outages, etc.) and can operate with minimal interruption. Data integrity means no data is lost or corrupted even in adverse scenarios. Here are strategies used by major platforms to achieve HA and integrity:
Redundant Deployment (No SPOF): Avoid single points of failure at every layer. Facebook, LinkedIn, and Instagram run infrastructure in multiple data centers so that even if an entire data center goes offline, the service stays up[2]. LinkedIn by 2015 was operating out of three main data centers (plus edge PoP sites)[2]. Traffic is distributed such that if one site fails, others can pick up the load. Within each site, critical components are clustered (multiple instances of application servers behind LBs, database clusters with failover replicas, etc.). For example, the Instagram main DB has 12 replicas across zones[1] – these replicas not only serve read traffic but act as hot standbys; if the master fails, a replica can be promoted. To design an ERP for HA, deploy at least in an active-active configuration across two or more regions (with data replication), or an active-passive disaster recovery site at minimum. All servers should be at least duplicated, and use quorum or consensus for leader election in cluster management to avoid depending on one node.
Graceful Failure and Fault Isolation: In large systems, things will go wrong – networks partition, machines crash, bugs cause processes to hang. The key is to fail gracefully and isolate faults so they don’t cascade. Techniques include circuit breakers in service calls (stop calling a downstream service if it’s unresponsive, to avoid thread pile-ups), timeouts and retries for external requests, and graceful degradation of features. For instance, if the reporting module of the ERP is down, the rest of the system should continue running (maybe with a warning that some reports are delayed). Facebook has in the past served user data in “read-only mode” during certain maintenance – an ERP might similarly fall back to read-only for critical data if the primary DB is in trouble, rather than being completely offline. Bulkheading is another approach: separate components so that a failure in one (say, an analytics job running wild) doesn’t starve resources for others (production OLTP queries). Using containers or separate VMs for different services can enforce resource isolation. LinkedIn’s move to microservices helped here – each service could be scaled or fixed independently without bringing down the whole system[2][2].
Database Replication and Backups: Data is the lifeblood of an ERP, so multiple copies and backups are essential. All major platforms replicate data across machines and sites. Replication can be synchronous or asynchronous. Synchronous (often via distributed consensus) ensures no data is lost on a single failure, but can reduce performance if nodes are far apart. Asynchronous (master-slave) is higher throughput but may lose the last few transactions if the master dies unexpectedly. Many systems choose async replication with fast failover – the slight risk of losing a few seconds of data is acceptable for the huge performance gains, and you mitigate by writing frequent incremental backups. For example, Facebook’s MySQL data is copied to Hadoop HDFS regularly, effectively backing up the social graph[3]. They run one of the largest Hadoop clusters, ingesting around 2 PB of new data per day and storing MySQL backups across multiple clusters/data centers[3][3]. This shows the emphasis on having copies of data in separate failure domains. An ERP system should schedule nightly full backups and continuous incremental backups (e.g. WAL shipping) to an off-site location. Additionally, maintain at least one standby replica of each database that can be promoted in seconds or minutes if the primary fails. Regularly test restoration from backups to ensure data integrity (a backup is only as good as your ability to restore it).
Disaster Recovery and Multi-Data-Center Sync: In global services, disaster recovery (DR) plans involve not just data backup but keeping a whole secondary site ready. LinkedIn’s infrastructure evolved to support one-way data replication events and callbacks between data centers, and they explicitly prepared all services to run in multiple sites with user “pinning” to a home DC[2]. This implies that LinkedIn can recover from losing a region by routing users to another region’s servers and still have their data (perhaps slightly behind) available. They note that having multi-DC deployment improved availability and disaster recovery capabilities[3]. For the ERP, define RPO/RTO (Recovery Point and Time Objectives). For example, RPO of a few seconds (meaning a few seconds of data might be lost in a disaster) and RTO of an hour (system back up in an hour at new site) might be achievable with asynchronous replication and automated failover. Some organizations achieve near-zero RPO/RTO with synchronous replication and automated failover, but at high cost/complexity. At minimum, maintain off-site backups and a standby environment that can be activated.
Data Integrity Measures: To avoid data corruption or divergence, especially when multiple copies exist, platforms use checksums, consistency checks, and constrained write patterns. Facebook’s Wormhole system, for instance, ensures atomicity of update events with the originating DB transaction (only publishing to subscribers if the DB write succeeded)[7]. It also guarantees at-least-once ordered delivery of changes to keep caches in sync[7]. In an ERP, to maintain integrity across distributed components (e.g. stock levels in inventory service vs. accounting), you might use atomic database transactions across those records or an event sourcing mechanism with idempotent consumers. Furthermore, implement strict unique constraints and referential integrity in the database to prevent duplicate or inconsistent entries (this pairs with the sequence generation strategies in the next section to avoid, say, duplicate invoice numbers).
Monitoring and Quick Mitigation: All large sites invest heavily in monitoring and incident response to catch issues before they become outages. Instagram uses tools like Munin for resource monitoring and StatsD for custom application metrics, alerting the team to anomalies in real time[1][1]. They also use external uptime monitors (Pingdom) and on-call alert systems (PagerDuty)[1]. An ERP deployment should include robust monitoring of server health, database performance (slow query logs, replication lag), queue lengths, error rates, etc. coupled with automated alerts. This ties into HA by enabling operators or automated scripts to react (e.g. auto-restart a crashed service, or route traffic away from a lagging DB).
Graceful Degradation: If a component fails, degrade functionality instead of total failure. For example, if the search service in the ERP is down, show results from a last known index or display a message that search is temporarily limited – but allow core transactions to continue. Facebook in its chat system found sending presence notifications for every friend going online/offline didn’t scale (it would have to send enormous numbers of updates)[4][4]. Instead of trying and failing, they adjusted the design (clients pull a batch of online friends periodically)[4]. The philosophy is to reduce feature set under strain rather than complete downtime. Feature flags and toggles can disable non-essential features if the system load is too high, preserving the critical functions.
In summary, high availability for a large-scale ERP means multi-site redundancy, automated failover, and eliminating single failures, while data integrity means robust replication, backups, and consistency checks. By following the patterns of global tech firms – multiple data centers, replication of every critical piece, continuous monitoring – the ERP can achieve near-zero downtime and safeguard its data against loss.
4. Request Distribution and Load Balancing
When millions of users access a service, incoming requests must be efficiently distributed across many servers. Load balancing is critical both locally (within a data center) and globally (across regions). Key considerations include balancing algorithms, failover handling, minimizing latency, and handling user sessions.
Load Balancer Types: Large systems often use a combination of load balancers. Hardware load balancers (like F5 BIG-IP appliances) were traditionally used in front of web farms for their high throughput and reliability. For instance, LinkedIn scaled its early services by “spinning up new instances… and using hardware load balancers between them”[2]. Over time, software LBs have become popular: HAProxy, Nginx, Envoy are commonly deployed L4/L7 proxies that distribute traffic based on various algorithms (round-robin, least connections, etc.). Cloud providers offer managed LB services (AWS ELB/ALB, Azure Application Gateway, GCP Load Balancing) which abstract away infrastructure. An ERP in a hybrid environment might use cloud load balancers at the edge to route traffic into on-prem data centers via VPN, or use DNS-based distribution (discussed below). At LinkedIn, they introduced multiple tiers of proxies – using Apache Traffic Server and HAProxy – to handle not only basic load balancing but also tasks like traffic routing between data centers, security, and request filtering[2]. Similarly, Facebook and Instagram use layered load balancing: DNS directs to a region, a layer of L4 balancers handles transport, and L7 proxies handle application-level routing and caching.
Global Traffic Distribution: For multi-region deployment, a Global Load Balancing strategy decides which data center a user’s request goes to. The goal is to route users to the nearest or best-performing region to reduce latency and balance load. Large platforms typically leverage DNS-based load balancing for this: systems like AWS Route53 Latency-Based Routing, Azure Traffic Manager, or GeoDNS respond to DNS queries with an IP of a regional entry point based on the user’s location or system health[8]. For example, LinkedIn served some content from multiple data centers by first routing users to the closest site (they mention starting by serving public profiles from two data centers as a trial)[2]. Another method is Anycast networking – advertising the same IP address from multiple locations; the internet routes users to the nearest instance. Cloudflare’s network, for instance, uses anycast to ensure users connect to the closest of their 300+ cities, achieving ~50ms latency globally[9][9]. An ERP can use a simpler approach if it has, say, one Americas and one Europe data center: use DNS geo-routing to send European users to the EU site and American users to the US site. Each site will handle traffic locally, but they must stay in sync on data (as discussed earlier). In case one site fails, DNS can failover all traffic to the surviving site (though this may cause higher latency for some users). The global load balancer should also consider capacity – if one region is overloaded, it might spill some traffic to another region.
Local Load Balancing & Health Checks: Within a data center or region, a load balancer distributes incoming requests to many application server instances. Common algorithms are round-robin (each server in turn), least connections (to send to the least busy server), or weighted (if servers have different capacities). Load balancers also perform health checks – periodically pinging servers or test endpoints – to detect down instances and stop sending traffic to them. This failover mechanism is crucial: if a server crashes or is taken down for deploy, the LB detects it and automatically reroutes traffic to others, with minimal user impact. LinkedIn’s service discovery (D2) combined with client-side load balancing allows their services to route around failed instances as well[2]. For a Python ERP, one might use HAProxy or Nginx as an LB in front of Gunicorn/uWSGI app servers. The LB would be configured with checks (e.g. an HTTP health check URL that the app responds to) and multiple backend servers. In a cloud scenario, one could use an AWS Application Load Balancer which provides built-in health checks and automatic failover.
Session Persistence (Sticky Sessions) vs. Stateless: If a user’s session data is stored in-memory on a specific server, the load balancer must consistently send that user to the same server (“sticky sessions”). However, sticky sessions reduce the effectiveness of load balancing (some servers might get more load due to many returning users bound to them) and make recovery harder (if that server dies, those users lose session state). The preferred approach, as mentioned earlier, is to keep the web tier stateless. For example, Instagram stores session data in Redis[1], an in-memory datastore accessible by all servers. This way, any web server can handle any user – they all consult the central Redis for session info. If using sticky sessions is unavoidable (perhaps due to legacy constraints), it should be implemented at the LB level with a fallback (like hashing a cookie to a server). Modern designs often use token-based sessions (JWTs or similar), where the client carries session state in a signed token and servers just validate it without storing server-side state. This eliminates the need for session affinity entirely. In summary, to maintain efficient load distribution, design your ERP’s session management such that any app server can serve requests in sequence for a given user (e.g. after login, the user’s auth token or session ID is valid on all servers).
Failover and Graceful Degradation: Load balancers can also distribute based on server responsiveness – e.g. if one instance starts responding slowly (high latency), the LB can shift load away. Some sophisticated setups use adaptive load balancing that takes into account server response times. Additionally, if an entire service is down (say the report generation service), the API gateway or LB might direct those requests to a placeholder or an error page quickly, rather than timing out. Facebook’s multi-tier proxy setup likely incorporates logic to route around faults and even shed traffic if needed to protect the core services[2]. An ERP might implement an API gateway that if it cannot reach a microservice (e.g. inventory service), it returns a cached response or a clear error to the user without hanging the whole request.
Content Delivery and Latency Reduction: A special kind of load balancing involves using Content Delivery Networks (CDNs) for static assets (images, scripts, downloads). CDNs like Cloudflare, Akamai host copies of content in edge servers around the world, drastically reducing latency for users. LinkedIn, for example, began caching template data and assets in CDNs and browsers to improve performance for global users[2]. For a large ERP, static content (product images, PDFs, etc.) can be offloaded to a CDN or cloud storage with CDN in front. This takes significant load off the core servers and speeds up content delivery by serving from edge locations.
Example – LinkedIn’s Traffic Management: LinkedIn’s modern architecture uses DNS load balancing for global traffic, then Apache Traffic Server (ATS) and HAProxy as reverse proxies at each data center for local load balancing and routing[2]. They also pin users to a home data center to maintain data locality (which reduces cross-data-center calls)[2]. This kind of multi-level load balancing (global DNS -> regional proxy -> local service cluster) ensures both high availability and optimal latency.
Scaling to Millions of Requests: The combination of techniques above allows systems like Facebook to handle enormous request volumes. Every request first hits a load balancer which might distribute to dozens of web servers, which in turn call dozens of downstream services – all orchestrated such that no single machine is overwhelmed. For our Python ERP, we should ensure that we can run many application instances in parallel behind load balancers. Cloud auto-scaling groups could add instances on demand when traffic spikes, and the LB will automatically include them (if using a cloud LB). On-prem, one can use orchestration (Kubernetes or custom scripts) to monitor load and start more containers/VMs as needed, updating the LB’s backend pool.
In summary, use load balancers at every entry point: global routing (via DNS or anycast) to direct users to the nearest/healthy region, and local load balancers or reverse proxies to spread load among app servers and handle failures. Keep services stateless or externalize state so that load balancing is free to do its job. By following these practices, the ERP can serve millions of users with low latency and high reliability, even under uneven or surge traffic patterns.
5. Concurrency and Sequence Control
In a distributed ERP deployment, ensuring unique sequences (IDs, invoice numbers, etc.) and avoiding conflicts is a non-trivial challenge. Multiple servers or databases operating in parallel can lead to duplicate keys or inconsistent ordering if not carefully designed. Platforms like Twitter, Facebook, and Instagram have developed methods to generate unique IDs at massive scale without central bottlenecks. We can adopt similar strategies:
Unique ID Generation: Many large systems move away from simple auto-increment IDs (which are tied to a single DB instance) to distributed ID generators. One popular approach is Twitter’s Snowflake algorithm, which creates 64-bit unique IDs composed of a timestamp, machine identifier, and sequence number[10][10]. This ensures IDs are unique across the whole system and roughly ordered by time (monotonic increasing) without a central authority. In Snowflake’s typical schema:
- Bits layout: 41 bits timestamp, 10 bits for combined datacenter+machine ID, 12 bits sequence (reset each millisecond)[10][10].
- Each generator (running on each service instance or a set of ID servers) can produce up to 2^12 (4096) IDs per millisecond, and the timestamp provides ordering[10][10].
- Instagram adopted a variant of Snowflake for their ID generation when they sharded their Postgres – using timestamp, a logical shard ID, and a per-shard sequence in the ID composition[5][5]. They had 41 bits of time, 13 bits of shard ID, and 10 bits of sequence[5], enabling 1024 IDs per shard per millisecond. These IDs (64-bit integers) are unique and sortable, and generation is distributed to each DB shard (each shard’s Postgres sequence contributes the sequence bits)[5][5]. This method avoids any single point of coordination – each shard or node can generate IDs independently as long as their system clocks are roughly in sync (and clock drift beyond a few ms is handled by waiting or sequence rollover logic). For an ERP, implementing a Snowflake-like service (there are open-source implementations in various languages) would allow, say, all invoices to have globally unique IDs without hitting a central DB sequence.
UUIDs (Universally Unique IDs): Another straightforward method is using UUIDs, 128-bit globally unique identifiers. UUID v4 (random) or v1 (time-based with MAC address) can be generated independently by any node with an astronomically low probability of collision (practically zero). The advantage is there’s no coordination needed at all – truly decentralized[10][10]. Many NoSQL databases (MongoDB, Cassandra) default to UUID-style keys to avoid coordination[11]. The downside is that UUIDs are large (128-bit) and not ordered (unless using time-based versions), which can lead to index bloat and fragmentation in databases. Also, for things like invoice numbers which often have meaning (or need ordering), random UUIDs are not ideal. However, they are excellent for uniqueness. An approach some systems take is to use UUIDs for internal identifiers (ensuring uniqueness across shards) but maintain a shorter sequential number per tenant or per year for human-facing documents (with a mapping stored in a database). If ordering is not critical, UUIDs are a simple solution: e.g., generating a UUID for each new user or transaction in a distributed system guarantees no conflict.
Database-Aided Strategies (Auto-increment Offsets): Traditional SQL databases can still be used in creative ways to generate unique IDs across multiple instances. One strategy in a multi-master SQL setup is to configure auto-increment with different offsets on each master. For example, with two master databases, one could generate only odd IDs and the other only even IDs (auto-increment step=2, offset=1 vs offset=2)[5]. With four servers, one would increment by 4 and start at 1, another start at 2, 3, 4, so their sequences interleave but never collide[11][11]. This was historically used by some systems (Flickr did this with two masters). It ensures uniqueness, but the IDs are not strictly time-ordered across servers (one server’s higher-number ID might actually be older than another server’s lower ID)[5]. Moreover, if you add or remove servers, reconfiguring the offsets is difficult (hence not auto-scalable)[11][11]. This method could be employed if, say, an ERP had regional databases issuing IDs – each region could have its ID range (e.g., prefix or offset) to avoid collision. However, managing sequence alignment as regions scale up or down adds complexity. It’s generally a medium-term fix if you have a known number of nodes.
Centralized ID Service (“Ticket Server”): Some systems implement a central ID generator service (also called a ticket server). This is essentially a service (or a DB sequence on one designated database) that all other services call to get the next ID. It ensures global ordering and uniqueness by serializing ID generation in one place[11][11]. However, it can become a single point of failure and a bottleneck if not scaled. One can have multiple redundant ID servers (to avoid single point of failure), but then coordinating between them becomes an issue (they could dole out ranges or have one as primary and others as standby). Some payment systems choose this approach because they need strictly sequential order numbers with no gaps – a central service can ensure each new transaction gets the next number with 100% consistency[11]. If using this in an ERP, it’s wise to mitigate risk by using a block allocation strategy: the central service hands out blocks of IDs to each app server (e.g., 1000 at a time), so that the app server can generate from that block quickly and only go back to the central service when it runs out. This reduces contention and impact of the central service. Still, care must be taken to persist any unused ranges if a server dies.
Conflict Avoidance in Multi-DB Writes: Beyond just IDs, conflicts can occur if two different database nodes attempt to modify the same record or violate a unique constraint simultaneously. To avoid this in a distributed ERP, one tactic is to partition the responsibility – for example, if a user’s data is always handled by a particular server or shard (as LinkedIn does by pinning users to a home data center)[2], then conflicting operations on that user are funneled to one place. In multi-master databases, use conflict resolution policies: e.g., “last write wins” (with timestamps) or merge rules for things like counters (additive). Some modern databases (CouchDB, Dynamo-style systems) allow divergent writes and then resolve via application-provided resolution or CRDTs (Conflict-free Replicated Data Types) – but implementing these can be complex and may not be needed for ERP transactional data. It’s often simpler to serialize contentious operations through a single leader. For instance, a globally distributed ERP might designate one region as the “leader” for creating new customer accounts to ensure no two regions create accounts with the same username. Alternatively, use a distributed lock service (like Apache Zookeeper or etcd) – e.g., to ensure uniqueness of a username, all regions could coordinate via a lock or a consensus to agree on creation one-at-a-time. However, distributed locking can become a throughput bottleneck itself.
Tools and Libraries: Many languages and ecosystems provide libraries for unique ID generation. For Python, one could use packages for Snowflake IDs or UUID (Python’s uuid module). Databases like MongoDB use a 12-byte ObjectID (which includes a timestamp, machine ID, and counter) – an approach similar to Snowflake but encoded differently. That’s another blueprint: ObjectIDs are globally unique and sort by time. The ERP could adopt Mongo-style IDs even if not using MongoDB. Also, consider using time-based prefixes for human-readable sequences (e.g., invoice numbers often incorporate year or date). This can reduce collision domain and also give an implicit order. For example, invoice “2025-INV-000001” – the “2025” part means a new sequence each year. Each year could safely start from 1 without conflicting with past years, and if multiple regional servers generate invoices, as long as they include a region code or different range, they won’t clash.
Summary: Achieving global uniqueness and order requires either coordination or clever encoding. The most scalable solutions (Snowflake, ObjectID, UUID) avoid centralized locks and instead embed enough information in the ID to make collisions virtually impossible. We recommend using a Snowflake-like service for the ERP to generate primary keys (especially for things like InvoiceID where business requires uniqueness). This gives you time-sortable, 64-bit IDs that can scale to huge volumes[11]. Use UUIDs where ordering isn’t important but a quick unique token is needed (session IDs, random keys). And for things that need human-friendly sequences, implement them per scope (e.g., per company or year) or use a small central coordinator with range allocation. The approaches outlined (and used at Twitter/Instagram/etc.) will ensure your ERP avoids painful issues like duplicate invoice numbers or mismatched counters even when running across many servers.
6. Authentication and Authorization
Handling user authentication and authorization in a multi-region, large-scale system requires a secure, centralized approach that remains low-latency for users around the world. Key challenges include keeping authentication data in sync, avoiding multiple logins if users switch regions, and managing sessions or tokens across distributed servers.
Centralized Identity Management: Large platforms typically have a central auth service or user database that serves as the source of truth for credentials and permissions. For example, when you log into Facebook or LinkedIn, your credentials are checked against a central user store. In a multi-region setup, that doesn’t necessarily mean one physical database – the user database can be replicated globally, but logically it’s a single system (with user IDs unique across the whole platform). The ERP should similarly use a unified user directory (say a central PostgreSQL or LDAP for users/roles) accessible from all regions. To achieve low latency, one approach is to replicate authentication data to each region (or at least an encrypted cache of password hashes, etc.), so that login doesn’t always require cross-ocean calls. Facebook’s approach to similar problems has been deploying systems like memcache or proprietary caches to each data center that store frequently accessed data (user sessions, tokens)[1]. Indeed, Instagram co-locates cache servers with web servers in each data center to avoid latency on reads[1]. For authentication, a distributed session cache (e.g., Redis cluster) could hold active session tokens in memory in each region, updated on login.
Low-Latency Login: Users expect quick login responses. To ensure this in a distributed ERP, it might use a strategy like authenticate once, use tokens thereafter. On initial login, if the auth service is centralized in, say, the home region, the user’s credentials might be checked there. But after successful login, the system issues a signed token (JWT or similar) to the user. This token can be self-contained (including user ID, roles, expiry) and signed by the central authority. Thereafter, any regional server can validate the token locally (using public key or secret) without a database lookup, achieving constant-time auth checks. This is similar to how OAuth JWTs or API tokens work in many services – they allow decentralized verification. It also means if the user travels or is served by a different data center on the next request, they won’t need to log in again; the token is globally valid. One caveat: revocation or logout can be tricky with stateless tokens (you might need a revocation list or short token lifetimes). Alternatively, one can use a session identifier stored in a cookie that maps to a server-side session store (like a Redis key). That requires lookups, but if the session store is replicated globally (or partitioned by region with replication), any region can fetch the session data. Instagram’s use of Redis for session storage is a real example – presumably a user’s session object can be retrieved by any web server from Redis, making the login “follow” the user[1].
Regional Authentication Flow: Another design is to route authentication requests to a single region (like a “central login server”). For instance, a user hitting a EU server to log in might have their credentials forwarded to the global auth service (perhaps in the US) which verifies and returns a token. This introduces a bit of latency on login but login is infrequent relative to other interactions, and once the token is issued subsequent requests don’t incur that cost. This model simplifies consistency (only one place to check passwords) but requires robust global connectivity. Many systems use an approach like: /login API is served only by a central cluster (or a global microservice), whereas other APIs are served regionally with token auth.
Single Sign-On (SSO) and Federation: In enterprise scenarios, users might be authenticated via SSO (e.g., integrating with an identity provider like Active Directory, Okta, etc.). In a multi-region ERP, the application would redirect to the central SSO authority for login, then get a SAML or OAuth token that is accepted platform-wide. The advantage is that it leverages an existing centralized directory and can incorporate MFA, etc. It also naturally produces a token that is valid anywhere. The drawback could be complexity and reliance on external systems, but it’s worth noting if the ERP is for large organizations, supporting SSO is key.
Authorization (Permissions): Beyond authentication, ensuring correct authorization is vital especially as the system grows (who can approve an invoice, who can access certain data). Typically, a role-based access control (RBAC) system is implemented, often also centralized. For example, a user’s roles or group memberships might be stored in the central auth database and included in their token or retrievable on the fly. At scale, permission checks should be cached as well – e.g., if a user’s roles are in the JWT, each service can enforce based on those claims without DB calls. If more dynamic, a service like Amazon’s Cognito or Azure AD can manage distributed auth, but one can also custom-build lightweight permission services.
Session Management Techniques: As mentioned, using stateless tokens (like JWT) is a common choice for distributed session management. It pushes the state to the client and avoids server-side session storage entirely (aside from perhaps a central token blacklist for logouts). Another technique is sticky sessions at the global level – but this gets complicated. For example, you could pin a user to always hit their home region’s servers for the duration of their session to avoid cross-region issues (LinkedIn did user pinning to a data center[2]). This ensures that all of a user’s interactions (in that session) go to one regional DB (reducing multi-master conflicts). The downside is if the user travels or if that data center is down, you need a re-pinning strategy. It’s simpler for an ERP to use the token approach and allow any region to serve the user, relying on the distributed data being consistent or using a global lookup for any missing info.
Protecting Against Authentication Threats: Large systems also incorporate measures like rate limiting login attempts, using CAPTCHAs or MFA for suspicious logins, and securely hashing and salting passwords (e.g., using bcrypt or Argon2). These should all apply to the ERP. Storing passwords in a single secure vault (and replicating the hash DB read-only as needed) is better than having multiple divergent user stores.
Example – Instagram Authentication: While details aren’t public about Instagram’s auth, we know that Instagram (as part of Facebook) allows using Facebook accounts to log in as well. In the context of architecture: Instagram’s stateless frontends and use of Redis for sessions suggests they issue a session cookie that is recognized by all web servers[1]. If the user’s request hits a different server, it can fetch session info from Redis by session ID and authenticate the user. This is effectively a distributed session store approach.
Example – LinkedIn Scale: LinkedIn had to handle hundreds of millions of users logging in. After migrating to microservices, they likely use a central service for handling credentials. They also implemented systems like Galene for relevance and perhaps used it to check contextual permissions (Galene was more for feed ranking though). While specific auth architecture isn’t detailed in our sources, we can infer that things like 100 billion REST calls per day[2] all had to be authenticated. This volume suggests that the overhead per call must be minimal (likely token-based auth with lightweight verification).
Distributed Authorization: One challenge is if certain actions need coordination – e.g., generating a globally unique sequential invoice number on the fly might require checking a central sequence (ties back to concurrency control). But for general read/write operations, each service can enforce permissions on its own data domain as long as the user’s roles/claims are known.
Keeping Authentication Highly Available: The auth system itself should be HA – multiple replicas of the user DB, multiple instances of the token issuance service, etc. If using JWTs, you’ll have a key (or key pair) for signing; manage those keys carefully (rotate, distribute the public key to all services). One best practice is using stateless auth to reduce dependency on central systems – once a user is authenticated, even if the central auth DB goes down, existing tokens remain valid until expiration, allowing the system to continue functioning for logged-in users.
In conclusion, for a scalable ERP: centralize authentication but distribute verification. Use a single source for user credentials and identity (ensuring one username = one user globally), but after login, rely on secure tokens or distributed session stores so that any server in any region can authenticate requests without heavy cross-region communication. This yields a low-latency, scalable auth system. Also implement strong security practices (encryption, hashing, MFA support) since at large scale, auth will be a prime target for attacks.
7. Notification and Messaging Systems
Large-scale platforms send enormous numbers of notifications and handle real-time messaging between users. For an ERP, notification systems might include emails (invoices, reminders), SMS alerts, push notifications, and in-app messages or updates (e.g. a dashboard updating when new data arrives). Achieving this reliably for millions of events requires decoupling via messaging infrastructure.
Asynchronous Processing for Notifications: A common theme is to use message queues and background workers for sending notifications. Instead of sending an email or SMS inline during a user request, the system enqueues a notification task to be processed by worker servers. This way, user-facing actions aren’t slowed by external email gateways or push services. A Reddit discussion on scaling notifications succinctly states: “you use asynchronous messaging. You push the notification into a queue and then workers consume those messages to do the work of sending notifications… Almost every scaling issue for non-real-time problems can be fixed by queueing and scaling workers”[12][12]. Instagram follows this model: they use RabbitMQ with Celery workers to handle tasks like sending notifications, fan-out updates, and other background jobs[1]. When a user performs an action that triggers notifications (say, approval of a purchase order triggers emails to relevant managers), the web server would post a message to a queue like “send email X to user Y” and immediately return to other work. A fleet of dedicated notification worker processes will pull that message and execute the actual sending (via SMTP server or third-party API). This allows throughput to be scaled by simply adding more worker processes when notification volume grows, as the Reddit CTO described (monitor queue length and add workers as needed)[12].
Email and SMS at Scale: For email, one might integrate with services such as Amazon SES, SendGrid, or run a cluster of mail servers. At high scale, ensure to handle bouncebacks and throttling. For SMS, integration with providers like Twilio or direct carrier gateways is common. These external interactions are rate-limited, so a queuing system helps smooth out bursts. Bulk notifications (like end-of-month statements to all customers) should be processed in batches via workers to avoid spamming or overloading any single provider or IP – again something a queue + worker design handles by controlling concurrency.
Push Notifications: If the ERP includes a mobile app component or uses web push, push notifications would be sent via Apple’s APNs or Google FCM. Typically a push notification service is built that accepts internal events and then communicates with APNs/FCM. This service too can be scaled horizontally. It often keeps a connection pool to the push servers (APNs uses HTTP/2 nowadays; FCM has its endpoints). High-volume push systems use multiple worker instances to maintain many simultaneous connections and throughput. They also handle feedback (device tokens invalid, etc.) and update the database accordingly.
Real-Time In-App Messaging: For features requiring realtime updates (e.g., a notification bell icon that updates when a new approval is required, or a live chat within the ERP), technologies like WebSockets, Server-Sent Events (SSE), or long-polling are used. Facebook’s chat originally used long-poll (Comet) to achieve near-real-time delivery[4][4]. They establish long-lived HTTP connections and push data as it becomes available. The architecture of Facebook Messenger uses a “channel server” cluster (written in Erlang) to manage persistent connections and message queueing for realtime chat[4][4]. Each message is given a sequence number and queued/delivered via these channel servers, which are optimized for massive concurrency (Erlang is used for its lightweight process model and fault tolerance)[4]. While an ERP may not need a full chat system, it could benefit from a WebSocket-based notification server to instantly push events (like “Inventory low for Product XYZ” pop-ups). Python can handle WebSockets (e.g., via frameworks like Django Channels or libraries like websockets/Tornado), but one might also consider a specialized service (even in another language or using a SaaS like Pusher) if expecting huge scale.
Event Streaming (Internal): Within the backend, high-volume event streaming platforms like Apache Kafka are often used to move data between services in near real-time. LinkedIn created Kafka to unify their event pipelines for things like tracking page views, updating search indexes when profiles change, delivering InMail, etc.[2][2]. Kafka is essentially a distributed publish-subscribe log where producers write events and many consumers can read them. In our ERP context, Kafka (or similar systems like RabbitMQ, AWS Kinesis, Google Pub/Sub) could be used to broadcast events such as “InvoiceCreated” or “StockLevelChanged” to any interested service. For example, when an invoice is paid (event in finance module), an inventory service could consume that event to release reserved stock, a CRM service could consume it to update customer purchase history, and a notification service could send a confirmation email – all asynchronously, loosely coupled via the event bus. Kafka is known for its ability to handle millions of events per second; LinkedIn reported Kafka was handling over 500 billion events per day by mid-2015[2]. That scale shows the reliability of decoupling via logs – you can add more consumers without impacting the producers. For a Python-based solution, one could use Kafka with a Python client (like confluent-kafka), or RabbitMQ for simpler queue needs. RabbitMQ is often used for task queues (as with Instagram Celery) while Kafka shines for high-throughput publish-subscribe scenarios and streaming.
Fan-out and Delivery Guarantees: When a single action triggers notifications to many recipients (fan-out), a message broker is useful to distribute workload. For example, a manager approves a request and 50 people need to be notified – rather than the app server looping to send 50 messages, it can publish one event that 50 consumers (or a consumer that then creates 50 tasks) will handle. Systems like Kafka and RabbitMQ ensure durability of messages (so they won’t be lost even if a service restarts, as long as they’re configured with persistence and replication). This is crucial for integrity – if you queue 1,000 emails to customers, you want to be sure they’ll eventually get sent even if there’s a crash. Design the notification system with at-least-once delivery (it’s okay if an email might rarely send twice, but not okay if it’s lost – so handle duplication on the consumer side if needed by checking a send log).
Real-Time Dashboard Updates: Beyond user messaging, an ERP might have real-time dashboards that refresh when new data comes in (e.g., new orders update the sales chart). Implementing this could leverage WebSockets or SSE to push updates to browser clients. Another approach is polling via AJAX at intervals, which is simpler but less efficient at scale. A modern approach is to have the client subscribe to updates (could be via WebSocket or even GraphQL subscriptions) and the server push deltas. Under the hood, that could be tied into the same event system – e.g., when a new order is created, an event triggers not just backend processes but also is sent to a WebSocket server that then notifies all connected admin dashboards.
Infrastructure for Messaging: The “plumbing” includes ensuring you have brokers/servers set up: e.g., a Kafka cluster (with multiple brokers) if needed for scale, or RabbitMQ cluster (RabbitMQ can be clustered for HA). Also, Redis is sometimes used as a lightweight pub/sub or stream (Redis Streams feature) for simpler cases. Facebook has an internal pub-sub (Wormhole) to propagate data changes across systems and data centers in real-time[7][7]. Wormhole specifically helps keep caches synchronized and search indexes updated by sending cache invalidation messages and updates whenever user data changes[7][7]. It handles over 1 trillion messages per day on their user database streams[7]. This underscores that internal messaging is not just for user-facing features but also for maintaining consistency and efficiency behind the scenes. For our ERP, a scaled-down equivalent could be to send cache invalidation events to all app servers when certain data is updated, so they can invalidate any local caches – ensuring that globally, users see fresh data quickly (an approach also achievable with a tool like Redis or Hazelcast for distributed cache coherence).
Monitoring and Managing Notification Systems: At scale, you also need to monitor the queues – number of pending messages, processing rates, failures. If an email service is down and emails queue up, alerting should notify the ops team. Implement retries with backoff for external sends (if an email send fails, retry a few times, then maybe give up and log an error for manual intervention). Use DLQs (Dead Letter Queues) for messages that consistently fail processing, so they don’t block the main queue.
In summary, the strategy is: decouple notification and messaging from the main flow using queues and pub-sub. Use background workers to handle high volume sends (as Instagram does with RabbitMQ/Celery)[1], and use real-time push channels (WebSocket/SSE) for instant updates to users where needed, possibly powered by a specialized service like Facebook’s Channel servers for chat[4][4]. Adopting proven technologies like Kafka for event streaming and RabbitMQ for task distribution will allow the ERP to reliably deliver thousands or millions of notifications daily, and to update users in real-time, all while keeping the core system responsive.
8. Practical Application Guidance
Bringing these strategies together, here are best practices and design principles for building a Python-based ERP system that is scalable, consistent, and highly available, with concrete guidance drawn from the successes of Facebook, LinkedIn, Instagram, and others:
- Modular, Service-Oriented Design: Architect the ERP as a set of services or modules (financials, inventory, CRM, etc.) rather than one giant program. This follows the microservice philosophy used by LinkedIn and Facebook[3]. Each module can have its own data store and can be scaled or updated independently. Clearly define APIs between modules. Start with a modular monolith if necessary (for simplicity), but with logical separation that can be pulled apart later.
- Stateless Application Layer: Design web/application servers to be stateless and horizontally scalable. Leverage frameworks like Django (as Instagram did)[1] or Flask/FastAPI for Python, but avoid storing user-specific data on local disk or memory. Externalize session state (use Redis or tokens) and file storage (use a distributed filesystem or cloud storage). This allows running many app servers behind load balancers, and performing rolling deployments with zero downtime. LinkedIn’s stateless services and use of load balancers allowed them to scale by just adding instances[2].
- Use Caching Wisely: Introduce caching at multiple levels to reduce database load and improve response times. Implement an in-memory cache layer (Redis or Memcached) for frequent reads, as all three companies do (Facebook with memcache[3], Instagram with memcache/Redis[1], LinkedIn with Voldemort/Memcached[2]). However, design cache invalidation carefully to maintain consistency (consider using pub-sub like Facebook’s Wormhole to invalidate caches across instances quickly[7][7]). Cached data should have appropriate TTL or be explicitly cleared on updates. Aim to cache read-heavy, not-often-changing data (e.g., reference tables, user profiles), but be cautious with highly dynamic data.
- Robust Database Architecture: Use a relational database as the core source of truth for transactional integrity (e.g., PostgreSQL or MySQL). Implement master-replica replication for scaling reads and ensuring high availability (Instagram’s DB had 12 replicas[1]; LinkedIn uses multiple replicas and eventually partitioning[2]). Plan a sharding strategy early – even if you start with one DB, design your schema and code to accommodate sharding by key (like user or company). Consider using schema-based sharding (Instagram’s approach)[5] or application-level sharding through a data access layer. For global deployment, decide between a single global database (with potential latency) vs. multiple regional databases (with eventual consistency). Many opt for one primary region for writes and read replicas in others to balance the trade-offs.
- Ensure Unique Constraints and Avoid Duplicates: To prevent duplicate entries (like invoice numbers or user IDs), implement a reliable unique ID generation approach. A distributed ID generator (Snowflake-like) is recommended for scale, as discussed earlier[11]. This prevents collisions without a centralized bottleneck. Additionally, enforce database constraints (unique indexes on invoice number, etc.) as a safety net – if two entries somehow try the same ID, the DB will reject one. Use transactions around creating such records, so that any race conditions are resolved by the DB (one succeeds, the other can retry with a new ID). In cases where strict sequential numbering is needed (audits often require no gaps in invoice numbers), you might maintain a small service or a dedicated DB sequence and carefully manage it (possibly partitioned by region or year). The key is that every path to create a new invoice goes through a single allocator (be it an algorithm or service), so duplicates are inherently avoided.
- High Availability Setup: Deploy the ERP in at least a primary and secondary data center, or in multiple availability zones if on cloud, to withstand failures. Use load balancers with health checks to automatically remove failed nodes[2]. Set up database failover (e.g., MySQL with auto-promotion of replicas, or use cloud-managed DB that handles failover). Implement continuous backups and perhaps geo-replication of data (Facebook does multi-DC replication for DR[3]). Practice disaster recovery drills – e.g., simulate the primary DB going down and ensure the secondary can take over without data loss (the backup strategy at Facebook processes huge volumes to keep up[3]).
- Graceful Degradation and Testing: Include feature toggles to turn off non-critical features if the system is under extreme load. For example, you might disable generation of PDF reports during peak hours if it strains the system, with a notice to users, while keeping core operations running. Test the system under load (perform load testing to 10x expected load to see where bottlenecks arise[12]) and under failure (use chaos testing principles: kill instances, break network connections to ensure the system handles it gracefully).
- Security and Auth at Scale: Implement secure authentication with modern practices (hashing, salting, TLS everywhere). Use centralized auth and issue tokens so that the system scales (as noted, token auth avoids DB hits on every request). If using JWTs, include necessary user roles/permissions in them for quick authorization checks. Regularly review permission logic to avoid privilege escalation especially when multiple services are involved (a zero-trust approach internally can help: each service validates the permissions even if another service calls it). Monitor auth events for abuse (rate-limit login attempts per IP to prevent brute force).
- Leverage Python’s Strengths and Mitigate Weaknesses: Python enables rapid development (as seen with Instagram using Django to quickly build features[1]) and has a rich ecosystem (Celery for task queue, NumPy/Pandas for analytics, etc.). However, Python’s single-thread performance is limited (due to GIL). To scale compute-intensive tasks, use multi-processing or offload to worker processes – which aligns with the distributed architecture anyway. Use asynchronous frameworks (asyncio, FastAPI) for IO-bound tasks to handle more concurrent requests with fewer threads, if needed. Also consider integrating languages better suited for certain tasks (e.g., use a C library for heavy number crunching, or use Node/Go for a specialized WebSocket service) – many big systems are polyglot (LinkedIn mostly Java, some Node, etc., and they interoperate via REST/Thrift APIs[2]).
- Logging, Monitoring, and Analytics: Build comprehensive logging into the ERP from day one. Use an ELK stack or cloud logging to aggregate logs. Metrics (qps, latency, error rates, DB load, queue lengths) should be collected – similar to how Instagram tracks metrics with StatsD and internal counters for signups, likes, etc.[1]. This helps in tuning performance and catching issues early. As data grows, have a plan for analytics – maybe periodically offload data to a warehouse (like Instagram archiving to Hive[1]) so that running heavy reports doesn’t bog down the live system.
- Continuous Evolution: Expect that the architecture will evolve over years. LinkedIn’s journey included multiple paradigm shifts (monolith to microservices, introducing Kafka, multi-DC support)[2][2]. Design with change in mind: use interfaces that can be swapped (e.g., data access layer that could switch from single DB to sharded DB or to a NewSQL store without changing business logic). Keep an eye on emerging tech – for instance, NewSQL databases or cloud-native services might simplify some aspects in the future. However, also rely on proven components (scaling issues often arise from reinventing wheels that companies like Facebook have already solved).
- Documentation and Diagrams: As part of practical implementation, maintain clear architecture diagrams and documentation (similar to the ones referenced here for Instagram and LinkedIn). This helps onboarding team members and communicating the design. For example, create diagrams showing how an invoice creation request flows from the user, through load balancers, to app servers, to the DB, and then triggers a background email via the queue. Having these “mental models” drawn out ensures nothing is overlooked and aids in troubleshooting.
By following these best practices and learning from the architectures of major platforms, a Python-based ERP can be engineered to handle millions of users, across hybrid cloud and on-premise deployments, with reliable performance and room to grow. The emphasis should be on scalability (horizontal scaling, caching, async processing), consistency where needed (transactions, careful sharding, global IDs), and resilience (redundancy, failover, monitoring). Each design choice – from the database to the load balancer to the messaging system – contributes to a system that can gracefully handle both high load and long-term growth.
No comments yet. Login to start a new discussion Start a new discussion