
بناء نظام ERP واسع النطاق: دروس من Facebook و LinkedIn و Instagram
لتصميم نظام ERP قوي يمكنه التوسع ليشمل ملايين المستخدمين عبر المناطق ويتطور على مدى سنوات، من المفيد دراسة كيفية تعامل المنصات الرائدة مع الاستخدام المكثف والمتزامن للبيانات. يُلخص هذا التقرير استراتيجيات من Facebook و LinkedIn و Instagram – مع التركيز على البنية التحتية، إدارة البيانات، التوافر العالي، موازنة التحميل، التحكم في التزامن، الأمان، المراسلة، والإرشادات العملية للتصميم. الهدف هو هندسة ERP مبنية على Python (مناسبة للنشر السحابي الهجين / داخل المنشأة) تحقق أداءً عالياً، اتساقاً، وتوافرًا واسع النطاق.
1. البنية التحتية وهندسة النظام
السحابة الهجينة مقابل النظام المحلي (On-Premise): غالبًا ما تستفيد المنصات الكبيرة من كلاً من السحابة ومراكز البيانات الخاصة لتحقيق قابلية التوسع والتحكم. على سبيل المثال، كان Instagram يعمل في البداية على AWS ولكنه انتقل لاحقًا إلى مراكز بيانات Facebook الخاصة لتقليل الكمون والتكامل مع بنية Facebook[1]. يمكن أن تستفيد أنظمة ERP من هذا النهج الهجين: توفر موارد السحابة المرونة للوصول العالمي، بينما تتولى الخوادم المحلية التعامل مع البيانات الحساسة أو التكامل مع الأنظمة القديمة. يجب أن تكون البنية التحتية مخصصة للحاويات ومنسقة (مثل Kubernetes) للنشر السلس عبر بيئات السحابة والمحلية.
أدوار وطبقات الخوادم: عادةً ما يُقسم النظام القابل للتوسع إلى طبقات من الخوادم المتخصصة: خوادم الويب / التطبيقات، عمال الخلفية، خوادم قواعد البيانات، تخزين الملفات، وعقد التخزين المؤقت. في نظام Instagram الخلفي (وهو تطبيق Django Python ضخم)، تتعامل خوادم الويب عديمة الحالة (تشغيل Django) مع الطلبات خلف موازن تحميل Nginx[1]
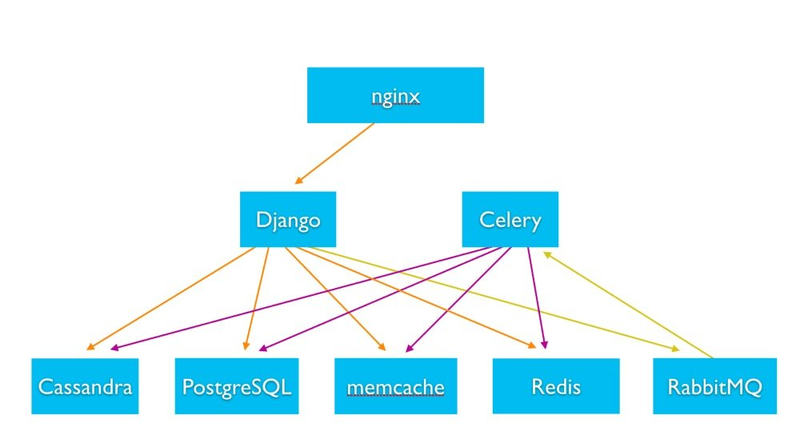
يُعالج خوادم العمل غير المتزامنة (Celery workers) الوظائف الخلفية[1]. تُدار البيانات عبر طبقات تخزين مخصصة – قواعد بيانات علائقية، مخازن NoSQL، ذاكرات تخزين مؤقت داخل الذاكرة، وتخزين الملفات / الكائنات. على سبيل المثال، يستخدم Instagram PostgreSQL كقاعدة بيانات علائقية رئيسية، وCassandra (NoSQL) للتخزين الموزع، وMemcache و Redis للتخزين المؤقت، وRabbitMQ للمراسلة[1]. يتم تحسين كل نوع من الخوادم حسب دوره (مثلاً خوادم قواعد البيانات بأقراص سريعة، وخوادم التخزين المؤقت بذاكرة RAM عالية).
هندسة Instagram المبسطة: خوادم ويب Python عديمة الحالة (Django) وعمال المهام (Celery) يتفاعلون مع أنظمة خلفية متنوعة (SQL، NoSQL، التخزين المؤقت، المراسلة)[1][1]. يسمح هذا الفصل في المسؤوليات بالتوسع المستقل لكل مكون (إضافة المزيد من خوادم الويب للمستخدمين المتزامنين، إضافة نسخ قواعد بيانات أو عقد تخزين مؤقت للوصول إلى البيانات) وصيانة أسهل.
الأنظمة المصغرة مقابل النظام الأحادي (Monolith): مع نمو قاعدة المستخدمين، تطورت كل من Facebook و LinkedIn من البنى الأحادية إلى بنى معمارية موجهة بالخدمات المصغرة لمزيد من المرونة وقابلية التوسع. بدأ LinkedIn كنظام أحادي (“Leo”) لكنه تم تقسيمه لاحقًا إلى خدمات عديمة الحالة متعددة (مبادرة “Kill Leo”) لتحسين الاعتمادية وسرعة التطوير[2][2]. تركز كل خدمة مصغرة على مجال معين (الملفات الشخصية، البحث، المراسلة، إلخ)، وتتواصل مع الخدمات الأخرى عبر واجهات برمجة تطبيقات محددة. يعمل Facebook بطريقة مشابهة بمعمارية “ loosely coupled ” حيث تكون الميزات مثل الصور، المراسلة، وتغذية الأخبار خدمات منفصلة، غالبًا مع قواعد بيانات خاصة بها[3]. يمكن لنظام ERP قائم على الخدمات المصغرة تقسيم الوحدات (المالية، الموارد البشرية، المبيعات) إلى خدمات تتوسع بشكل مستقل ويمكن تطويرها / نشرها بالتوازي. تتواصل الخدمات عبر REST/HTTP أو أطر RPC. (قدم LinkedIn Rest.li لواجهات RESTful موحدة عبر الفرق[2]، بينما بنى Facebook Thrift لـ RPC متعدد اللغات[4].)
التوسع عديم الحالة (Stateless Scaling): تعد خاصية عديم الحالة مفتاحًا للتوسع الأفقي. يجب أن تتجنب الخدمات تخزين بيانات الجلسة المحددة في الذاكرة بحيث يمكن لأي مثيل التعامل مع أي طلب. يؤكد كل من LinkedIn و Instagram على طبقات ويب عديمة الحالة – يمكن لأي خادم تقديم الخدمة لأي مستخدم خلف موازن تحميل[2][1]. تُحفظ حالة المستخدم (الجلسات، التخزين المؤقت) في مخازن مشتركة (قواعد بيانات، Redis، إلخ) بدلًا من الذاكرة المحلية. بهذه الطريقة، يعني التوسع ببساطة إضافة المزيد من المثيلات خلف موازن التحميل، دون الحاجة إلى تعقيدات في تخصيص الجلسات. كما يبسط التصميم عديم الحالة استعادة الأعطال: إذا توقف خادم، يمكن للخادم التالي معالجة الطلبات دون فقدان الجلسة.
الاتصال والتكامل: في نظام موزع يحتوي على العديد من الخوادم والخدمات، تعتبر أنماط الاتصال الداخلي الواضحة أمرًا حيويًا. تستخدم العديد من المنصات الكبيرة المراسلة غير المتزامنة أو أنظمة اكتشاف الخدمة لربط المكونات. على سبيل المثال، تستخدم خدمات LinkedIn طبقة اكتشاف وموازنة تحميل (D2) لتوجيه الطلبات إلى مثيلات الخدمة[2]، وتتواصل خدمات Facebook عبر Thrift RPC، مما يمكّن الوحدات المكتوبة بلغات مختلفة (C++، PHP، Erlang، إلخ) من التفاعل[4]. بالنسبة لنظام ERP مبني على Python، قد تُستخدم واجهات RESTful APIs (مثل نقاط نهاية Flask/FastAPI) أو gRPC لاستدعاءات الخدمات الداخلية. تفصل المراسلة غير المتزامنة (طوابير الرسائل أو ناقلات الأحداث) المكونات – المزيد حول هذا في قسم الإشعارات.
مثال – هندسة متعددة الطبقات: تشمل الهندسة النموذجية واسعة النطاق طبقات متعددة من الخدمات والتخزين المؤقت. كان لدى هندسة LinkedIn المتطورة (حوالي 2015) تطبيقات ويب أمامية، وطبقة خدمة متوسطة (واجهات برمجة منطق الأعمال)، وخدمات بيانات خلفية تتعامل مع قواعد البيانات[2][2]. يُطبق التخزين المؤقت على مستويات مختلفة: استخدمت ذاكرات تخزين مؤقت داخل الذاكرة مثل Memcached أو Couchbase لتقليل الحمل على قواعد البيانات[2]، وانتقلت LinkedIn في النهاية إلى الاحتفاظ بالتخزين المؤقت “بالقرب من البيانات” (التخزين المؤقت في طبقة الوصول إلى البيانات) للبساطة[2]. تم دمج أنظمة مثل Voldemort (مخزن قيمة-مفتاح مفتوح المصدر من LinkedIn) و Kafka (لتدفق البيانات) للوصول عالي الإنتاجية ونقل البيانات[2][2]. يوضح الرسم البياني أدناه هندسة خدمة متعددة الطبقات مع واجهات أمامية، وخدمات متوسطة، وخدمات بيانات خلفية باستخدام قواعد البيانات والتخزين المؤقت.
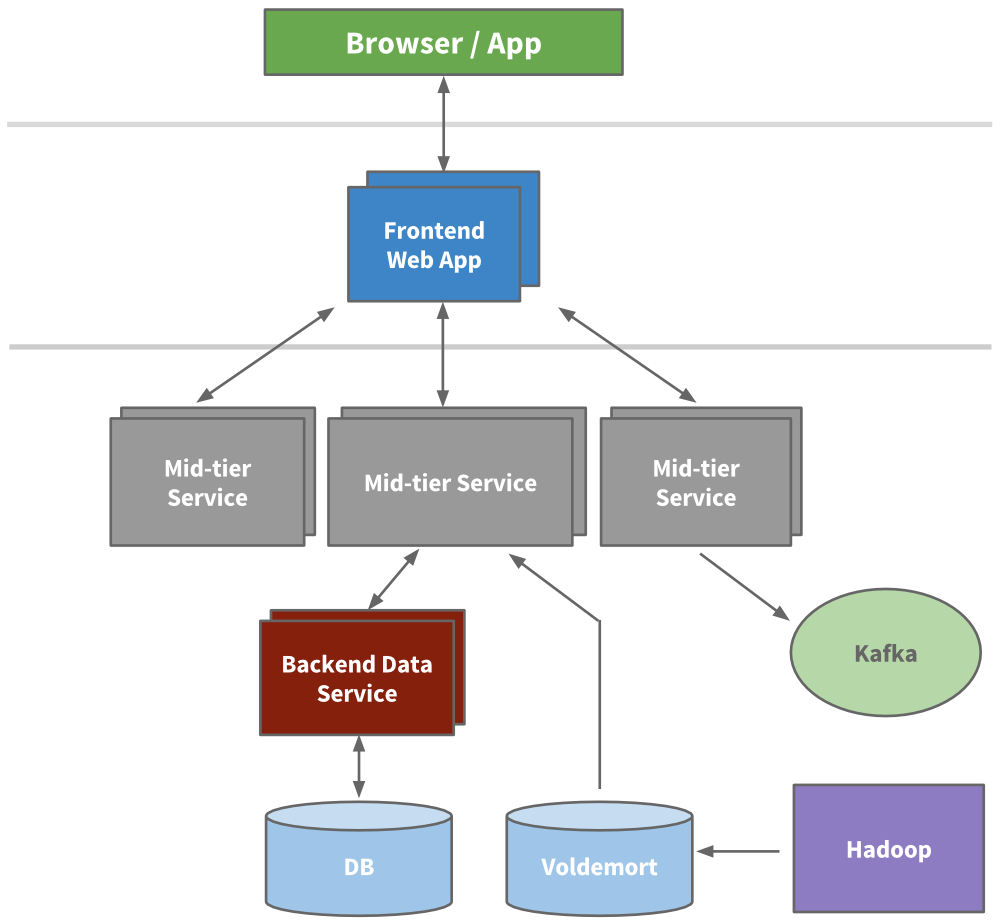
هندسة متعددة الطبقات توضيحية (مستوحاة من LinkedIn): تضرب طلبات العميل خادم ويب أمامي، الذي يستدعي خدمات متعددة متوسطة الطبقة. تقوم هذه بدورها بجلب البيانات من خدمات بيانات خلفية (لكل منها قاعدة بيانات أو مخزن خاص). تساعد التخزينات المؤقتة الموزعة (مثل Voldemort) وخط أنابيب المراسلة (Kafka) في التعامل مع حمل القراءة وانتشار البيانات[2][2]. يعزل هذا التدرج المسؤوليات ويسمح لكل طبقة بالتوسع أفقيًا.
ملخص البنية التحتية: يجب أن تستخدم البنية التحتية لنظام ERP ضخم نشرًا عنقوديًا عبر مناطق متعددة، مع توسعة كل طبقة خدمية. استخدم تصميمات عديمة الحالة لخوادم الويب / التطبيقات، استخدم خوادم متخصصة لقواعد البيانات، التخزين المؤقت، والمهام غير المتزامنة، واربطها بشبكات موثوقة أو شبكة خدمات. يضمن هذا النهج في التوسع المعياري، الذي تستخدمه شركات مثل Facebook و LinkedIn، قدرة النظام على التعامل مع النمو ببساطة عن طريق إضافة سعة في الطبقة المطلوبة.
2. أنظمة واستراتيجيات قواعد البيانات
التخزين متعدد اللغات (Polyglot Persistence): لا توجد تقنية قاعدة بيانات واحدة تناسب جميع الاحتياجات على نطاق واسع. منصة Facebook مثال رئيسي على التخزين متعدد اللغات – باستخدام مخازن بيانات مختلفة لأنواع مختلفة من البيانات[3][3]. MySQL (علائقية) هي المخزن الأساسي لبيانات الشبكة الاجتماعية (مع محرك تخزين RocksDB مخصص للكفاءة)[3]. يُضاف Memcached أمام MySQL لتخزين النتائج مؤقتًا وتقليل حمل القراءة[3]. بالنسبة للتحليلات واسعة النطاق وتسجيل الدخول، تلجأ Facebook إلى مستودع بيانات Hadoop/Hive وقاعدة بيانات HBase (NoSQL على نمط bigtable) لإدارة بيتابايتات من البيانات[3][3]. تستخدم بعض الميزات مخازن متخصصة: مثلاً Cassandra (مخزن أعمدة واسع NoSQL) تم تطويره أصلاً في Facebook للبحث في صندوق البريد وهو موزع بطبيعته ومتحمل للأخطاء[3][3]. يتم التعامل مع بيانات المراقبة الزمنية بواسطة مخازن مخصصة مثل Gorilla أو Beringei[3]. يسمح هذا الأسلوب المختلط لكل نظام فرعي باستخدام نموذج البيانات الأمثل (SQL للمعاملات المنظمة، NoSQL للكتابة العالية أو المخططات المرنة، التخزين المؤقت في الذاكرة للسرعة، إلخ). يمكن لنظام ERP اعتماد استراتيجية مماثلة: استخدام RDBMS (PostgreSQL/MySQL) للمعاملات المالية التي تتطلب اتساق ACID، NoSQL أو محرك بحث للاستعلام المرن (مثل البحث النصي الكامل للسجلات)، ومخزن بيانات للأرشفة والتحليلات.
الأساس العلاقي مع التقسيم (Sharding): يُظهر النظام الخلفي لـ Instagram كيف يمكن لقاعدة بيانات علائقية تقليدية التوسع مع تقسيم البيانات والنسخ الاحتياطي بعناية. يستخدم Instagram PostgreSQL كقاعدة بيانات أساسية لتخزين الملفات الشخصية، المنشورات، الوسوم، إلخ[1]. مع نمو حجم البيانات إلى مليارات السجلات، تم تقييم بدائل NoSQL ولكنهم قسموا قاعدة بيانات PostgreSQL لتوسيع التوسع أفقيًا[1]. يعني التقسيم تقسيم البيانات إلى أجزاء عبر عدة خوادم قواعد بيانات (مثلاً، تقسيم المستخدمين أو الحسابات إلى عدة نسخ من قواعد البيانات). تنتشر المجموعة الرئيسية لقاعدة البيانات في Instagram عبر 12 نسخة ذات ذاكرة عالية في مناطق مختلفة[1] – مما يوفر قابلية التوسع في القراءة والتكرار. يتعامل كل جزء (Shard) مع مجموعة فرعية من المستخدمين، مما يقلل الحمل على كل قاعدة بيانات. كما طبقوا التقسيم المنطقي: تُقسم البيانات إلى أجزاء منطقية كثيرة (مثل تجزئة معرف المستخدم) يتم تعيينها إلى عدد أقل من خوادم قواعد البيانات الفيزيائية. يسمح ذلك بنقل الأجزاء المنطقية بين الخوادم حسب تغير الحاجة إلى السعة، دون تعطيل على مستوى التطبيق[5][5]. استفاد Instagram من مخططات Postgres لتمثيل الأجزاء المنطقية، ولكل جدول في كل جزء تسلسلات معرف خاصة – مما يبسط إنشاء المعرفات الفريدة لكل جزء ويتجنب تعارض المفاتيح الأساسية عبر الأجزاء[5][5]. بالنسبة لنظام ERP عالمي، يمكن لاستراتيجية تقسيم مماثلة أن تقسم البيانات حسب المنطقة، العميل، أو المجال الوظيفي (مثلاً أجزاء منفصلة لوحدات الأعمال المختلفة)، مع الوصول إليها جميعًا من خلال طبقة وصول بيانات موحدة.
تصميم المخطط للقدرة على التوسع: يجب أن يوازن تصميم المخطط بين التطبيع (للحفاظ على الاتساق) وعدم التطبيع (لتجنب عمليات الربط المكلفة أثناء التشغيل). غالبًا ما تحتفظ المنصات الكبيرة على الويب بالبيانات العلائقية بشكل منظم في المخزن الأساسي، لكنها تستخدم نسخًا مكررة غير منظمة أو فهارس ثانوية للميزات التي تعتمد بشكل كبير على عمليات القراءة. على سبيل المثال، تحافظ بنية بحث Instagram على وثائق غير منظمة للمستخدمين، الوسوم (hashtags)، المواقع محسّنة لاستعلامات البحث، منفصلة عن البيانات الأساسية المنظمة[1]. تسمح هذه الوثائق (المخزنة في محرك بحث Unicorn، الذي تم نقله من Elasticsearch) بإجراء استعلامات سريعة تعتمد على مجموعات عبر الرسم البياني الاجتماعي[1]. في نظام ERP، قد تبقى البيانات المالية الأساسية منظمة في قاعدة بيانات SQL (لضمان الدقة)، بينما يمكن إعادة تنظيم بيانات التقارير بشكل دوري في سوق بيانات (data mart) للاستعلام السريع. كما أن الفهرسة والتقسيم أمران حيويان أيضًا: أضف فهارس للحقول التي تُستعلم بشكل متكرر، لكن احذر من زيادة عبء عمليات الكتابة؛ وقسم الجداول الكبيرة حسب التاريخ أو المستأجر لتحسين سهولة الإدارة.
التقسيم والوصول الموحد: عند استخدام قواعد بيانات متعددة أو أجزاء (shards)، يجب على التطبيق إخفاء هذا التعقيد خلف طبقة وصول بيانات أو خدمة. يعد نظام TAO الخاص بـ Facebook مثالًا على التجريد: فهو يقدم واجهة API موحدة للرسم البياني بينما يجلب البيانات من عدة أجزاء MySQL وخوادم التخزين المؤقت تحت الغطاء[6]. وبالمثل، فإن Espresso الخاص بـ LinkedIn هو مخزن بيانات موزع يوفر واجهة استعلام موحدة ولكنه يمكن أن يعمل مع تكرار متعدد-رئيسي عبر مراكز البيانات[2]. عمليًا، تقوم خدمة الدليل أو وظيفة التوجيه (غالبًا بناءً على تجزئة مفتاح أو البحث في خريطة الأقسام) بإرسال كل استعلام إلى الجزء الصحيح. قد تحافظ طبقة بيانات ERP على تعيين مثل "العميل 1001 في جزء قاعدة البيانات 3" بحيث لا يحتاج كود التطبيق إلى معرفة تفاصيل الجزء. يضمن التقسيم الشفاف إمكانية إضافة سعة أو تقسيم الأجزاء دون تغييرات كبيرة في التطبيق – يتم تحديث خريطة التوجيه، وتتولى الخوادم الجديدة جزءًا من الحمل.
اتساق البيانات العالمي: يطرح النشر متعدد المناطق تحديًا في الحفاظ على اتساق البيانات عالميًا. ينص مبدأ CAP على أننا غالبًا ما نضحي بالاتساق مقابل التوفر في الأنظمة الموزعة. يستخدم Facebook غالبًا تكرار القائد-التابع (master-slave) لبياناته العلائقية: تذهب عمليات الكتابة إلى الأساسي، وتنتشر إلى النسخ المتماثلة بشكل غير متزامن. ينتج عن ذلك اتساق نهائي عبر المناطق. من التأثيرات المعروفة أنه إذا تم تحديث قيمة في مركز بيانات آسيوي مثلاً، قد يرى المستخدم الذي يقرأ من ذاكرة تخزين مؤقت في الولايات المتحدة القيمة القديمة لفترة وجيزة حتى تتزامن الذاكرة المؤقتة/قواعد البيانات[3]. يتسامح Facebook مع هذا الاتساق غير الكامل لضمان بقاء الموقع عالي التوفر والأداء، مستخدمًا التخزين المؤقت لامتصاص معظم عمليات القراءة[3]. من ناحية أخرى، يدعم مخزن بيانات Espresso الخاص بـ LinkedIn تكرار متعدد-رئيسي مع معالجة النزاعات، للسماح بالكتابة المحلية في مراكز بيانات متعددة[2]. تستخدم أنظمة التكرار المتعدد تقنيات مثل متجهات النسخة أو تسوية الطوابع الزمنية لحل التحديثات المتزامنة، أو تخصص أقسامًا معينة لأسياد محددين (غالبًا تثبيت بيانات كل مستخدم إلى منطقة "المنزل" لتجنب النزاعات)[2]. بالنسبة لنظام ERP يتعامل مع معاملات مالية، الاتساق القوي أمر بالغ الأهمية – النهج الشائع هو توجيه كل الكتابات لسجل معين إلى عقدة رئيسية واحدة (لتسلسل المعاملات). يمكن للنسخ المتماثلة للقراءة فقط في مناطق أخرى خدمة الاستعلامات لتقليل الكمون، لكن قد تُوجه عمليات الكتابة إلى المنطقة الرئيسية أو تستخدم معاملات موزعة. توفر قواعد البيانات الحديثة مثل NewSQL (مثلاً Google Spanner، CockroachDB) معاملات متسقة عالميًا باستخدام بروتوكولات الإجماع، مع تعقيد أكبر. اعتمادًا على المتطلبات، قد يختار نظام ERP نموذج الاتساق النهائي لبعض البيانات غير الحرجة (مع تسوية خلفية) والاتساق القوي للبيانات المالية الحيوية.
الأرشفة والبيانات الباردة: مع مرور السنوات، سيجمع نظام ERP كميات ضخمة من البيانات التاريخية (طلبات، فواتير، سجلات). يمكن أن يؤدي تخزينها جميعًا في قاعدة البيانات الإنتاجية إلى تضخم التخزين وبطء الاستعلامات (بسبب حجم الفهارس الكبير، إلخ). الاستراتيجية الشائعة هي أرشفة البيانات الباردة إلى مخزن بيانات أو تخزين طويل الأمد، مع الحفاظ على قاعدة بيانات العمليات خفيفة. يستخدم Instagram، على سبيل المثال، Apache Hive (على Hadoop) لأرشفة البيانات[1]. تقوم وظيفة مجدولة بنقل البيانات القديمة من PostgreSQL إلى جداول Hive، حيث يمكن الاستعلام عنها للتحليلات لكنها لم تعد تؤثر على أداء المعاملات[1]. يمكن أن تعتمد الأرشفة على عمر البيانات أو أهميتها – مثلاً يمكن نقل السنوات المالية المغلقة من قاعدة بيانات ERP الحية إلى مخزن أرشيف أو دلائل S3، واسترجاعها عند الطلب. الأثر على الأداء إيجابي: الجداول النشطة الأصغر تعني استعلامات أسرع وفهرسة أسهل. ومع ذلك، يحتاج التطبيق إلى معرفة ما إذا كانت بعض الاستعلامات تتطلب جلب البيانات من الأرشيف (أو توفير واجهة تقارير منفصلة للبيانات التاريخية). جانب آخر من الأرشفة هو بيانات السجلات والأحداث – غالبًا ما تبث المنصات الكبيرة السجلات إلى مخازن البيانات في الوقت الحقيقي (تسلم قناة Wormhole الخاصة بـ Facebook تحديثات متدفقة إلى Hadoop/Hive بدلاً من التفريغ الدوري[7][7]). يمكن لنظام ERP استخدام بث أحداث مماثل لأرشفة كل معاملة في الوقت الحقيقي تقريبًا إلى مخزن احتياطي، مما يحسن الموثوقية ويخفف أعباء التحليلات من قاعدة البيانات الأساسية.
ملخص استراتيجيات قواعد البيانات: عمليًا، من المرجح أن يستخدم نظام ERP قابل للتوسع عنقود قاعدة بيانات SQL أساسية (مقسمة أو مجزأة حسب المنطقة/المستأجر)، معززة بـ التخزين المؤقت (لتخفيف عمليات القراءة) وربما مكونات NoSQL لحالات استخدام محددة (مثل مخزن مستندات للمرفقات أو قاعدة بيانات رسم بياني للعلاقات المعقدة). خطط نموذج البيانات للسماح بالتقسيم (تجنب الانضمامات المعقدة عبر الأجزاء أو استخدم خدمة مجمعة لدمج البيانات من أجزاء متعددة عند الضرورة). طبق التكرار والنسخ الاحتياطي لجميع مخازن البيانات، وأتمتة التبديل التلقائي للمرونة. باتباع أنماط المنصات الكبيرة – باستخدام قاعدة البيانات المناسبة لكل مهمة وتصميم مع مراعاة التوزيع – يمكن لنظام ERP إدارة النمو من آلاف إلى ملايين المستخدمين.
3. التوافر العالي وسلامة البيانات
يمكن أن يكون التوقف عن العمل وفقدان البيانات كارثيًا للأنظمة الكبيرة. يعني التوافر العالي (HA) أن النظام قادر على الصمود أمام الأعطال (تعطل الخوادم، انقطاع مراكز البيانات، إلخ) ويمكنه العمل بأقل انقطاع ممكن. تعني سلامة البيانات عدم فقدان أو تلف البيانات حتى في السيناريوهات السيئة. فيما يلي استراتيجيات تستخدمها المنصات الكبرى لتحقيق التوافر العالي والسلامة:
نشر مكرر (عدم وجود نقطة فشل واحدة): تجنب نقاط الفشل المفردة في كل طبقة. تدير Facebook و LinkedIn و Instagram البنية التحتية في مراكز بيانات متعددة بحيث إذا تعطّل مركز بيانات كامل، يستمر الخدمة[2]. كانت LinkedIn بحلول 2015 تعمل من ثلاثة مراكز بيانات رئيسية (بالإضافة إلى مواقع نقاط التواجد الحافة)[2]. يتم توزيع الحركة بحيث إذا تعطل موقع واحد، يمكن للمواقع الأخرى استيعاب الحمل. داخل كل موقع، تُجمّع المكونات الحرجة (عدة مثيلات لخوادم التطبيقات خلف موازنات التحميل، عنقود قواعد بيانات مع نسخ احتياطية للتبديل التلقائي، إلخ). على سبيل المثال، يحتوي قاعدة بيانات Instagram الرئيسية على 12 نسخة عبر المناطق[1] – تخدم هذه النسخ حركة قراءة فقط ولكنها تعمل كنسخ احتياطية ساخنة؛ إذا فشل الأساسي، يمكن ترقية نسخة احتياطية. لتصميم ERP مع توافر عالي، انشر على الأقل في تكوين نشط-نشط عبر منطقتين أو أكثر (مع تكرار البيانات)، أو موقع استرداد من كارثة نشط-خامل كحد أدنى. يجب تكرار جميع الخوادم على الأقل، واستخدام آلية تصويت أو إجماع لانتخاب القائد في إدارة العنقود لتجنب الاعتماد على عقدة واحدة.
الفشل السلس وعزل الأعطال: في الأنظمة الكبيرة، سوف تحدث مشاكل – انقسام الشبكات، تعطل الأجهزة، الأخطاء التي تسبب توقف العمليات. المفتاح هو الفشل بشكل سلس وعزل الأعطال حتى لا تتسرب إلى مكونات أخرى. تشمل التقنيات قواطع الدائرة في استدعاءات الخدمات (إيقاف استدعاء خدمة خلفية إذا كانت غير مستجيبة لتجنب تراكم الخيوط)، مهل وإعادة محاولات للطلبات الخارجية، وتدهور سلس للميزات. على سبيل المثال، إذا تعطل وحدة التقارير في نظام ERP، يجب أن يستمر بقية النظام في العمل (ربما مع تحذير بأن بعض التقارير متأخرة). قدم Facebook سابقًا بيانات المستخدمين في “وضع القراءة فقط” خلال صيانة معينة – يمكن لنظام ERP أن يعتمد وضع القراءة فقط للبيانات الحرجة إذا كان DB الأساسي يعاني من مشاكل بدلاً من التوقف الكامل. التقسيم (Bulkheading) هو نهج آخر: فصل المكونات بحيث لا يؤدي فشل في أحدها (مثلاً مهمة تحليلات خارجة عن السيطرة) إلى استهلاك موارد المكونات الأخرى (استعلامات OLTP للإنتاج). يمكن أن تفرض الحاويات أو الأجهزة الافتراضية المنفصلة لكل خدمة عزل الموارد. ساعد التحول إلى الخدمات المصغرة في LinkedIn هنا – حيث يمكن لكل خدمة أن تُوسع أو تُصلح بشكل مستقل دون إسقاط النظام بأكمله[2][2].
تكرار قواعد البيانات والنسخ الاحتياطية: البيانات هي شريان حياة نظام ERP، لذا تُعد النسخ والنسخ الاحتياطية المتعددة أمرًا أساسيًا. تقوم جميع المنصات الكبرى بتكرار البيانات عبر الأجهزة والمواقع. يمكن أن يكون التكرار متزامنًا أو غير متزامن. يضمن التكرار المتزامن (غالبًا عبر إجماع موزع) عدم فقدان أي بيانات عند حدوث فشل واحد، لكنه قد يقلل الأداء إذا كانت العقد بعيدة عن بعضها. يوفر التكرار غير المتزامن (master-slave) معدل نقل أعلى ولكنه قد يفقد آخر المعاملات إذا تعطل الأساسي فجأة. تختار العديد من الأنظمة التكرار غير المتزامن مع تبديل سريع – حيث يُقبل خطر فقدان بضع ثوان من البيانات مقابل مكاسب الأداء الهائلة، ويُخفف هذا الخطر عبر كتابة نسخ احتياطية متزايدة متكررة. على سبيل المثال، يتم نسخ بيانات MySQL في Facebook إلى Hadoop HDFS بانتظام، مما يشكل نسخة احتياطية فعالة للرسم البياني الاجتماعي[3]. لديهم واحد من أكبر عناقيد Hadoop، حيث يتم استيعاب حوالي 2 بيتابايت من البيانات الجديدة يوميًا وتخزين نسخ MySQL الاحتياطية عبر عدة عناقيد / مراكز بيانات[3][3]. يظهر هذا التركيز على وجود نسخ من البيانات في مجالات فشل منفصلة. يجب على نظام ERP جدولة نسخ احتياطية كاملة ليلية ونسخ احتياطية متزايدة مستمرة (مثل WAL shipping) إلى موقع خارج الموقع. بالإضافة إلى ذلك، حافظ على نسخة احتياطية واحدة على الأقل يمكن تفعيلها في ثوانٍ أو دقائق إذا فشل الأساسي. قم باختبار استعادة النسخ الاحتياطية بانتظام لضمان سلامة البيانات (فالنسخة الاحتياطية جيدة بقدر قدرتك على استعادتها).
استرداد الكوارث ومزامنة مراكز البيانات المتعددة: في الخدمات العالمية، تتضمن خطط استرداد الكوارث (DR) ليس فقط النسخ الاحتياطي للبيانات بل أيضًا الحفاظ على موقع ثانوي كامل جاهز. تطورت بنية LinkedIn التحتية لدعم تكرار البيانات أحادي الاتجاه ونداءات رد بين مراكز البيانات، وأعدوا جميع الخدمات صراحةً للعمل في مواقع متعددة مع “تثبيت” المستخدمين إلى مركز بيانات رئيسي[2]. هذا يعني أن LinkedIn يمكنه التعافي من فقدان منطقة من خلال توجيه المستخدمين إلى خوادم منطقة أخرى والحفاظ على بياناتهم (ربما متأخرة قليلاً) متاحة. يشيرون إلى أن وجود نشر متعدد لمراكز البيانات حسن التوافر وقدرات استرداد الكوارث[3]. بالنسبة لنظام ERP، حدد أهداف نقطة الاسترداد (RPO) والوقت (RTO). مثلاً، RPO لبضع ثوانٍ (أي يمكن فقدان بضع ثوان من البيانات في كارثة) وRTO لساعة (إعادة تشغيل النظام في ساعة في الموقع الجديد) قد يكونان ممكنين بالتكرار غير المتزامن والتبديل الآلي. تحقق بعض المؤسسات من RPO/RTO شبه صفر باستخدام التكرار المتزامن والتبديل الآلي، لكنه مكلف ومعقد. كحد أدنى، حافظ على نسخ احتياطية خارج الموقع وبيئة احتياطية يمكن تفعيلها.
إجراءات سلامة البيانات: لتجنب تلف البيانات أو التباين، خاصةً عند وجود نسخ متعددة، تستخدم المنصات مجموعات تحقق، فحوصات اتساق، وأنماط كتابة مقيدة. على سبيل المثال، يضمن نظام Wormhole الخاص بـ Facebook الذرية في أحداث التحديث مع معاملة قاعدة البيانات الأصلية (ينشر للمشتركين فقط إذا نجحت كتابة قاعدة البيانات)[7]. كما يضمن التسليم المرتب مرة واحدة على الأقل للتغييرات للحفاظ على تزامن التخزين المؤقت[7]. في نظام ERP، للحفاظ على السلامة عبر المكونات الموزعة (مثل مستويات المخزون في خدمة الجرد مقابل المحاسبة)، قد تستخدم معاملات قاعدة بيانات ذرية عبر هذه السجلات أو آلية تدوين أحداث مع مستهلكين ذوي خاصية التكرار. علاوة على ذلك، طبق قيود فريدة صارمة وسلامة مرجعية في قاعدة البيانات لمنع الإدخالات المكررة أو غير المتسقة (يترافق هذا مع استراتيجيات توليد التسلسل في القسم التالي لتجنب، مثلاً، أرقام الفواتير المكررة).
المراقبة والتخفيف السريع: تستثمر جميع المواقع الكبيرة بشكل كبير في المراقبة والاستجابة للحوادث لالتقاط المشكلات قبل أن تتحول إلى انقطاعات. يستخدم Instagram أدوات مثل Munin لمراقبة الموارد وStatsD لمقاييس التطبيقات المخصصة، مما ينبه الفريق إلى الشذوذ في الوقت الحقيقي[1][1]. كما يستخدمون مراقبات التوفر الخارجية (Pingdom) وأنظمة التنبيه للطوارئ (PagerDuty)[1]. يجب أن يتضمن نشر ERP مراقبة قوية لصحة الخادم، أداء قاعدة البيانات (سجلات الاستعلام البطيء، تأخر التكرار)، أطوال الطوابير، معدلات الخطأ، إلخ، مع تنبيهات آلية. يرتبط هذا بالتوافر العالي بتمكين المشغلين أو السكربتات الآلية من الاستجابة (مثلاً إعادة تشغيل خدمة تعطلت تلقائيًا، أو توجيه الحركة بعيدًا عن قاعدة بيانات متأخرة).
تدهور سلس للوظائف: إذا فشل مكون، قم بتقليل الوظائف بدلاً من الفشل الكلي. على سبيل المثال، إذا تعطل خدمة البحث في نظام ERP، اعرض النتائج من آخر فهرس معروف أو رسالة تفيد بأن البحث محدود مؤقتًا – لكن اسمح باستمرار المعاملات الأساسية. وجدت Facebook في نظام الدردشة الخاص بها أن إرسال إشعارات الوجود لكل صديق متصل / غير متصل لا يتوسع (كان يجب إرسال عدد هائل من التحديثات)[4][4]. بدلًا من المحاولة والفشل، عدلوا التصميم (يقوم العملاء بسحب دفعة من الأصدقاء المتصلين بشكل دوري)[4]. الفلسفة هي تقليل مجموعة الميزات تحت الضغط بدلاً من التوقف الكامل. يمكن لعناصر التحكم في الميزات (feature flags) والتبديلات تعطيل الميزات غير الأساسية إذا كان تحميل النظام مرتفعًا جدًا، مع الحفاظ على الوظائف الحرجة.
باختصار، يعني التوافر العالي لنظام ERP واسع النطاق وجود تكرار متعدد المواقع، تبديل تلقائي، والقضاء على نقاط الفشل المفردة، بينما تعني سلامة البيانات تكرارًا قويًا، نسخًا احتياطية، وفحوصات اتساق. باتباع أنماط شركات التقنية العالمية – مراكز بيانات متعددة، تكرار كل قطعة حرجة، ومراقبة مستمرة – يمكن لنظام ERP تحقيق توقف شبه صفري وحماية بياناته من الفقدان.
4. توزيع الطلبات وموازنة التحميل
عندما يصل ملايين المستخدمين إلى خدمة، يجب توزيع الطلبات الواردة بكفاءة عبر العديد من الخوادم. تعتبر موازنة التحميل أمرًا حيويًا محليًا (داخل مركز البيانات) وعالميًا (عبر المناطق). تشمل الاعتبارات الرئيسية خوارزميات التوازن، التعامل مع التبديل التلقائي، تقليل الكمون، وإدارة جلسات المستخدمين.
أنواع موازنات التحميل: غالبًا ما تستخدم الأنظمة الكبيرة مجموعة من موازنات التحميل. كانت موازنات التحميل المادية (مثل أجهزة F5 BIG-IP) تُستخدم تقليديًا أمام مزارع الويب لأدائها العالي وموثوقيتها. على سبيل المثال، قامت LinkedIn بتوسيع خدماتها المبكرة عن طريق “إنشاء مثيلات جديدة… واستخدام موازنات تحميل مادية بينها”[2]. مع مرور الوقت، أصبحت موازنات التحميل البرمجية شائعة: HAProxy، Nginx، Envoy هي وكلاء L4/L7 شائعة تستخدم خوارزميات توزيع مختلفة (التناوب، أقل الاتصالات، إلخ). تقدم مزودات السحابة خدمات موازنات تحميل مُدارة (AWS ELB/ALB، Azure Application Gateway، GCP Load Balancing) التي تخفي البنية التحتية. قد يستخدم نظام ERP في بيئة هجينة موازنات تحميل سحابية على الحافة لتوجيه الحركة إلى مراكز البيانات المحلية عبر VPN، أو يستخدم التوزيع القائم على DNS (المناقش أدناه). في LinkedIn، قدموا عدة طبقات من الوكلاء – باستخدام Apache Traffic Server و HAProxy – للتعامل ليس فقط مع موازنة التحميل الأساسية ولكن أيضًا مهام مثل توجيه الحركة بين مراكز البيانات، الأمان، وترشيح الطلبات[2]. بالمثل، تستخدم Facebook و Instagram موازنة تحميل متعددة الطبقات: يوجه DNS إلى منطقة، طبقة موازنات L4 تتعامل مع النقل، ووكلاء L7 يتعاملون مع توجيه التطبيق والتخزين المؤقت.
توزيع الحركة العالمي: لنشر متعدد المناطق، تحدد استراتيجية موازنة التحميل العالمية المركز الذي يُرسل إليه طلب المستخدم. الهدف هو توجيه المستخدمين إلى أقرب منطقة أو أفضلها أداءً لتقليل الكمون وموازنة الحمل. عادةً ما تستفيد المنصات الكبيرة من موازنة تحميل قائمة على DNS لذلك: أنظمة مثل AWS Route53 Latency-Based Routing، Azure Traffic Manager، أو GeoDNS ترد على استعلامات DNS بعنوان IP لنقطة دخول إقليمية بناءً على موقع المستخدم أو صحة النظام[8]. على سبيل المثال، خدمت LinkedIn بعض المحتويات من عدة مراكز بيانات من خلال توجيه المستخدمين أولاً إلى أقرب موقع (وذكروا بدء الخدمة عبر مركزين لمحتويات الملفات الشخصية العامة كتجربة)[2]. طريقة أخرى هي شبكات Anycast – الإعلان عن نفس عنوان IP من مواقع متعددة؛ يقوم الإنترنت بتوجيه المستخدمين إلى أقرب مثيل. تستخدم شبكة Cloudflare، على سبيل المثال، أيكاست لضمان اتصال المستخدمين بأقرب أحد أكثر من 300 مدينة لهم، محققة كمون ~50 مللي ثانية عالميًا[9][9]. يمكن لنظام ERP استخدام نهج أبسط إذا كان لديه، مثلاً، مركز بيانات في الأمريكتين وآخر في أوروبا: استخدم توجيه DNS الجغرافي لإرسال المستخدمين الأوروبيين إلى موقع الاتحاد الأوروبي والأمريكيين إلى موقع الولايات المتحدة. يدير كل موقع الحركة محليًا، لكن يجب أن تظل البيانات متزامنة (كما نوقش سابقًا). في حالة تعطل أحد المواقع، يمكن لـ DNS إعادة توجيه جميع الحركة إلى الموقع الباقي (رغم أن هذا قد يسبب كمونًا أعلى لبعض المستخدمين). يجب أن يأخذ موازن التحميل العالمي أيضًا في الاعتبار السعة – إذا كانت منطقة واحدة مثقلة بالحمل، فقد يحول بعض الحركة إلى منطقة أخرى.
موازنة التحميل المحلية وفحوصات الصحة: داخل مركز البيانات أو المنطقة، يقوم موازن التحميل بتوزيع الطلبات الواردة على العديد من مثيلات خوادم التطبيقات. الخوارزميات الشائعة تشمل التناوب الدوري (round-robin) (كل خادم بالتتابع)، أقل الاتصالات (إرسال الطلب إلى الخادم الأقل انشغالًا)، أو الوزن (إذا كانت للخوادم قدرات مختلفة). كما يقوم موازن التحميل بإجراء فحوصات الصحة – بفحص الخوادم أو نقاط النهاية بشكل دوري – لاكتشاف الخوادم المعطلة وإيقاف إرسال الحركة إليها. هذه الآلية مهمة جدًا: إذا تعطل خادم أو تم إيقافه للنشر، يكتشف موازن التحميل ذلك ويعيد توجيه الحركة تلقائيًا إلى خوادم أخرى مع تأثير ضئيل على المستخدم. يسمح نظام اكتشاف الخدمات الخاص بـ LinkedIn (D2) مع موازنة التحميل على جهة العميل لخدماتهم بتجاوز مثيلات فاشلة أيضًا[2]. في نظام ERP مبني على Python، يمكن استخدام HAProxy أو Nginx كموازن تحميل أمام خوادم تطبيقات Gunicorn/uWSGI. يتم تكوين موازن التحميل مع فحوصات (مثل عنوان URL لفحص الصحة تستجيب له التطبيقات) وعدة خوادم خلفية. في سيناريو السحابة، يمكن استخدام AWS Application Load Balancer الذي يوفر فحوصات صحة مدمجة وتبديل تلقائي.
ثبات الجلسة (الجلسات اللاصقة) مقابل اللا Stateful: إذا تم تخزين بيانات جلسة المستخدم في ذاكرة خادم معين، يجب على موازن التحميل إرسال هذا المستخدم دائمًا إلى نفس الخادم (“الجلسات اللاصقة”). لكن الجلسات اللاصقة تقلل من فاعلية موازنة التحميل (قد يحصل بعض الخوادم على حمل زائد بسبب المستخدمين العائدين المرتبطين بها) وتجعل التعافي أصعب (إذا تعطل الخادم، يفقد هؤلاء المستخدمون حالة الجلسة). النهج المفضل، كما ذكر سابقًا، هو إبقاء طبقة الويب عديمة الحالة (stateless). على سبيل المثال، يقوم Instagram بتخزين بيانات الجلسة في Redis[1]، وهو مخزن بيانات في الذاكرة متاح لجميع الخوادم. بهذه الطريقة، يمكن لأي خادم ويب التعامل مع أي مستخدم – جميعهم يستشيرون Redis المركزي لمعلومات الجلسة. إذا كان استخدام الجلسات اللاصقة لا مفر منه (ربما بسبب قيود قديمة)، فيجب تنفيذها على مستوى موازن التحميل مع خطة احتياطية (مثل تجزئة كوكي على خادم). التصميمات الحديثة غالبًا ما تستخدم جلسات تعتمد على الرموز (tokens) (JWT أو ما يشابهها)، حيث يحمل العميل حالة الجلسة في رمز موقع، وتقوم الخوادم فقط بالتحقق منه دون تخزين الحالة على الخادم. هذا يلغي الحاجة إلى ارتباط الجلسة بالكامل. باختصار، للحفاظ على توزيع الحمل بكفاءة، صمم إدارة جلسات ERP بحيث يمكن أي خادم تطبيق خدمة الطلبات بالتتابع لمستخدم معين (مثلاً بعد تسجيل الدخول، يكون رمز المصادقة أو معرف الجلسة صالحًا على جميع الخوادم).
التبديل التلقائي والتدهور السلس: يمكن لموازنات التحميل أيضًا التوزيع بناءً على استجابة الخادم – مثلاً إذا بدأ أحد المثيلات في الاستجابة ببطء (كمون عالي)، يمكن لموازن التحميل تحويل الحمل بعيدًا عنه. تستخدم بعض التكوينات المتطورة موازنة تحميل تكيفية تأخذ في الاعتبار أوقات استجابة الخادم. بالإضافة إلى ذلك، إذا كانت خدمة كاملة متوقفة (مثل خدمة توليد التقارير)، قد توجه بوابة API أو موازن التحميل تلك الطلبات إلى صفحة مؤقتة أو صفحة خطأ بسرعة بدلاً من انتظار انتهاء المهلة. من المرجح أن يحتوي إعداد البروكسي متعدد الطبقات في Facebook على منطق لتوجيه الطلبات حول الأعطال وحتى تقليل الحمل إذا لزم الأمر لحماية الخدمات الأساسية[2]. يمكن لنظام ERP تنفيذ بوابة API ترجع ردًا مخزنًا مؤقتًا أو خطأ واضحًا للمستخدم إذا لم تتمكن من الوصول إلى خدمة مصغرة (مثل خدمة المخزون) دون تعليق الطلب بأكمله.
توزيع المحتوى وتقليل الكمون: نوع خاص من موازنة التحميل يشمل استخدام شبكات توصيل المحتوى (CDNs) للأصول الثابتة (صور، سكريبتات، تحميلات). تستضيف CDNs مثل Cloudflare و Akamai نسخًا من المحتوى في خوادم الحافة حول العالم، مما يقلل الكمون للمستخدمين بشكل كبير. بدأت LinkedIn، على سبيل المثال، في تخزين بيانات القوالب والأصول في CDNs والمتصفحات لتحسين الأداء للمستخدمين العالميين[2]. لنظام ERP كبير، يمكن نقل المحتوى الثابت (صور المنتجات، ملفات PDF، إلخ) إلى CDN أو تخزين سحابي مع CDN في المقدمة. هذا يقلل الحمل بشكل كبير عن الخوادم الأساسية ويسرع تسليم المحتوى من مواقع الحافة.
مثال – إدارة حركة LinkedIn: تستخدم بنية LinkedIn الحديثة موازنة تحميل DNS للحركة العالمية، ثم Apache Traffic Server (ATS) و HAProxy كوكلاء عكسيين في كل مركز بيانات لموازنة الحمل المحلية والتوجيه[2]. كما يربطون المستخدمين بمركز بيانات “المنزل” للحفاظ على توطين البيانات (مما يقلل المكالمات عبر مراكز البيانات)[2]. يضمن هذا النوع من موازنة التحميل متعددة المستويات (DNS العالمي -> بروكسي إقليمي -> عنقود خدمة محلي) التوفر العالي والكمون الأمثل.
التوسع لملايين الطلبات: تتيح مجموعة التقنيات السابقة لأنظمة مثل Facebook التعامل مع حجم هائل من الطلبات. كل طلب يصطدم أولاً بموازن تحميل قد يوزعها على عشرات خوادم الويب، والتي بدورها تستدعي عشرات الخدمات الخلفية – جميعها منسقة بحيث لا تُجهد آلة واحدة. لنظام ERP مبني على Python، يجب ضمان إمكانية تشغيل عدة مثيلات تطبيق بالتوازي خلف موازنات التحميل. يمكن لمجموعات التوسع التلقائي السحابية إضافة مثيلات عند زيادة الحمل، وسيشملها موازن التحميل تلقائيًا (إذا كان يستخدم موازن تحميل سحابي). في بيئة محلية، يمكن استخدام التنسيق (Kubernetes أو سكربتات مخصصة) لمراقبة الحمل وبدء المزيد من الحاويات/الأجهزة الافتراضية حسب الحاجة، مع تحديث مجموعة الخوادم الخلفية لموازن التحميل.
باختصار، استخدم موازنات تحميل في كل نقطة دخول: التوجيه العالمي (عبر DNS أو أيكاست) لتوجيه المستخدمين إلى أقرب / أفضَل منطقة صحية، وموازنات تحميل محلية أو وكلاء عكسيين لتوزيع الحمل بين خوادم التطبيقات والتعامل مع الأعطال. حافظ على الخدمات عديمة الحالة أو استخرج الحالة خارجيًا حتى تتمكن موازنة التحميل من أداء وظيفتها. باتباع هذه الممارسات، يمكن لنظام ERP خدمة ملايين المستخدمين بزمن استجابة منخفض وموثوقية عالية، حتى تحت ظروف حمل غير متساوية أو مفاجئة.
5. التحكم في التزامن والتسلسل
في نشر ERP موزع، ضمان تسلسلات فريدة (معرفات، أرقام فواتير، إلخ) وتجنب النزاعات هو تحدٍ غير بسيط. تشغيل عدة خوادم أو قواعد بيانات بالتوازي قد يؤدي إلى مفاتيح مكررة أو ترتيب غير متناسق إذا لم يُصمم بعناية. طورت منصات مثل Twitter و Facebook و Instagram طرقًا لإنشاء معرفات فريدة على نطاق ضخم دون اختناقات مركزية. يمكننا اعتماد استراتيجيات مماثلة:
توليد معرفات فريدة: تنتقل العديد من الأنظمة الكبيرة بعيدًا عن المعرفات التلقائية البسيطة (المرتبطة بمثيل قاعدة بيانات واحد) إلى مولدات معرفات موزعة. أحد الأساليب الشهيرة هو خوارزمية Snowflake من Twitter، التي تنشئ معرفات 64-بت فريدة تتكون من طابع زمني، معرف جهاز، ورقم تسلسلي[10][10]. هذا يضمن أن المعرفات فريدة عبر النظام بأكمله ومرتبة تقريبًا زمنياً (تزايد أحادي) بدون سلطة مركزية. في مخطط Snowflake النموذجي:
- توزيع البتات: 41 بت للطابع الزمني، 10 بتات لمعرف مدمج لمركز البيانات+الجهاز، 12 بت للتسلسل (يُعاد تعيينه كل مللي ثانية)[10][10].
- يمكن لكل مولد (يعمل على كل مثيل خدمة أو مجموعة من خوادم المعرفات) إنتاج ما يصل إلى 2^12 (4096) معرفًا في كل مللي ثانية، ويوفر الطابع الزمني ترتيبًا[10][10].
- تبنّت Instagram نسخة من Snowflake لتوليد المعرفات عند تقسيم قاعدة بيانات Postgres الخاصة بهم – باستخدام الطابع الزمني، معرف شارد منطقي، وتسلسل لكل شارد في تركيب المعرف[5][5]. كان لديهم 41 بت للوقت، 13 بت لمعرف الشارد، و10 بت للتسلسل[5]، مما يسمح بإنشاء 1024 معرفًا لكل شارد في كل مللي ثانية. هذه المعرفات (أعداد صحيحة 64-بت) فريدة وقابلة للترتيب، ويتم التوليد موزعًا لكل شارد قاعدة بيانات (تساهم تسلسلات Postgres لكل شارد في بتات التسلسل)[5][5]. تتجنب هذه الطريقة وجود نقطة تنسيق مركزية – يمكن لكل شارد أو عقدة توليد المعرفات بشكل مستقل طالما أن ساعات النظام متزامنة تقريبًا (ويتم التعامل مع انحراف الساعة بأكثر من بضعة مللي ثوانٍ عن طريق الانتظار أو منطق تدوير التسلسل). بالنسبة لنظام ERP، فإن تنفيذ خدمة شبيهة بـ Snowflake (هناك تنفيذات مفتوحة المصدر بلغات متعددة) يسمح مثلاً لجميع الفواتير بأن تكون لها معرفات فريدة عالميًا دون الحاجة للرجوع إلى تسلسل مركزي في قاعدة البيانات.
UUIDs (المعرفات الفريدة عالميًا): طريقة أخرى بسيطة هي استخدام UUIDs، وهي معرفات 128-بت فريدة عالميًا. يمكن إنشاء UUID v4 (عشوائي) أو v1 (معتمد على الوقت وعنوان MAC) بشكل مستقل من قبل أي عقدة مع احتمال تصادم منخفض جدًا (عمليًا صفر). الميزة هي أنه لا حاجة لأي تنسيق مركزي على الإطلاق – لامركزية حقيقية[10][10]. تستخدم العديد من قواعد بيانات NoSQL (مثل MongoDB، Cassandra) المفاتيح بنمط UUID لتجنب التنسيق[11]. العيب هو أن UUIDs كبيرة (128-بت) وغير مرتبة (إلا إذا كانت من النسخ المعتمدة على الوقت)، مما قد يؤدي إلى تضخم وتجزئة في الفهارس داخل قواعد البيانات. أيضًا، لأشياء مثل أرقام الفواتير التي غالبًا ما تحمل معنى (أو تحتاج إلى ترتيب)، فإن UUIDs العشوائية ليست مثالية. ومع ذلك، فهي ممتازة للفرادة. بعض الأنظمة تستخدم UUIDs للمعرفات الداخلية (لضمان التفرد عبر الشاردات) لكنها تحافظ على أرقام متسلسلة أقصر لكل مستأجر أو لكل سنة للوثائق الموجهة للمستخدمين (مع تخزين الخريطة في قاعدة بيانات). إذا لم يكن الترتيب مهمًا، فإن UUIDs هي حل بسيط: مثل إنشاء UUID لكل مستخدم جديد أو معاملة في نظام موزع يضمن عدم وجود تعارض.
استراتيجيات بمساعدة قاعدة البيانات (تعديلات التزايد التلقائي): يمكن استخدام قواعد بيانات SQL التقليدية بطرق مبتكرة لتوليد معرفات فريدة عبر مثيلات متعددة. إحدى الاستراتيجيات في إعداد متعدد الماستر لـ SQL هي تكوين التزايد التلقائي مع إزاحات مختلفة على كل ماستر. على سبيل المثال، مع وجود قاعدتي بيانات ماستر، يمكن لأحدهما توليد معرفات فردية فقط والآخر زوجية فقط (خطوة التزايد=2، إزاحة=1 مقابل إزاحة=2)[5]. مع أربعة خوادم، يزيد كل واحد بمقدار 4 ويبدأ عند 1، 2، 3، 4 بحيث تتداخل تسلسلاتهم لكنها لا تتصادم أبداً[11][11]. تم استخدام هذا تاريخيًا في بعض الأنظمة (مثل Flickr مع قاعدتي ماستر). يضمن التفرد، لكن المعرفات ليست مرتبة زمنياً بدقة عبر الخوادم (قد يكون معرف ذو رقم أعلى من خادم ما أقدم فعليًا من معرف ذو رقم أقل من خادم آخر)[5]. علاوة على ذلك، إذا أضفت أو أزلت خوادم، فإن إعادة تكوين الإزاحات صعبة (وبالتالي ليست قابلة للتوسع تلقائيًا)[11][11]. يمكن استخدام هذه الطريقة إذا كان لدى ERP قواعد بيانات إقليمية تصدر معرفات – يمكن لكل منطقة أن يكون لها نطاق معرفاتها (مثلاً بادئة أو إزاحة) لتجنب التصادم. ومع ذلك، إدارة تزامن التسلسلات مع زيادة أو نقصان المناطق تضيف تعقيدًا. عمومًا، هو حل متوسط الأمد إذا كان لديك عدد معروف من العقد.
خدمة المعرف المركزية ("خادم التذاكر"): تنفذ بعض الأنظمة خدمة مولد معرف مركزية (تسمى أيضًا خادم التذاكر). هي في الأساس خدمة (أو تسلسل قاعدة بيانات في قاعدة بيانات واحدة مخصصة) تستدعيها جميع الخدمات الأخرى للحصول على المعرف التالي. تضمن الترتيب العالمي والتفرد عن طريق تسلسل توليد المعرف في مكان واحد[11][11]. ومع ذلك، قد تصبح نقطة فشل واحدة وعنق زجاجة إذا لم يتم توسيعها بشكل كافٍ. يمكن أن يكون لديك عدة خوادم معرف احتياطية (لتجنب نقطة الفشل المفردة)، لكن تنسيقها معًا يصبح مشكلة (قد يوزعون نطاقات أو يكون واحد رئيسي والآخرون في وضع الاستعداد). تختار بعض أنظمة الدفع هذا النهج لأنها تحتاج إلى أرقام طلبات متسلسلة صارمة بدون فجوات – يمكن لخدمة مركزية أن تضمن حصول كل معاملة جديدة على الرقم التالي بنسبة 100% من الاتساق[11]. إذا استخدمت هذا في نظام ERP، فمن الحكمة تقليل المخاطر باستخدام استراتيجية تخصيص الكتل: تعطي الخدمة المركزية كتل معرفات لكل خادم تطبيق (مثلاً 1000 معرف في المرة)، بحيث يمكن لخادم التطبيق توليد المعرفات من هذه الكتلة بسرعة ويعود إلى الخدمة المركزية فقط عند نفادها. هذا يقلل من التنافس وتأثير الخدمة المركزية. مع ذلك، يجب الحذر من حفظ أي نطاقات غير مستخدمة إذا تعطل خادم.
تجنب النزاعات في الكتابة متعددة قواعد البيانات: بخلاف المعرفات، قد تحدث نزاعات إذا حاولت عقدتي قاعدة بيانات مختلفتين تعديل نفس السجل أو انتهاك قيد تفرد في آن واحد. لتجنب ذلك في ERP موزع، هناك تكتيك هو تقسيم المسؤولية – على سبيل المثال، إذا كانت بيانات المستخدم تُعالج دائمًا بواسطة خادم أو شارد معين (كما يفعل LinkedIn بتثبيت المستخدمين على مركز بيانات المنزل)[2]، فإن العمليات المتنازعة على ذلك المستخدم تُوجّه إلى مكان واحد. في قواعد البيانات متعددة الماستر، استخدم سياسات حل النزاعات: مثل "الكتابة الأخيرة تفوز" (مع الطوابع الزمنية) أو قواعد الدمج لأشياء مثل العدادات (الإضافة). تسمح بعض قواعد البيانات الحديثة (CouchDB، أنظمة Dynamo) بالكتابات المتباينة ثم تحلها عبر آليات مقدمة من التطبيق أو CRDTs (أنواع بيانات متكررة خالية من النزاعات) – لكن تنفيذها قد يكون معقدًا وقد لا يكون ضروريًا لبيانات المعاملات في ERP. غالبًا ما يكون من الأبسط تسلسل العمليات المتنازعة عبر زعيم واحد. على سبيل المثال، قد يحدد ERP موزع عالميًا منطقة واحدة كـ "الزعيم" لإنشاء حسابات العملاء الجديدة لضمان عدم إنشاء حسابين بنفس اسم المستخدم في منطقتين مختلفتين. بدلاً من ذلك، استخدم خدمة قفل موزعة (مثل Apache Zookeeper أو etcd) – مثلاً لضمان تفرد اسم المستخدم، يمكن لكل المناطق التنسيق عبر قفل أو إجماع للموافقة على الإنشاء بالتتابع. لكن الأقفال الموزعة قد تصبح عنق زجاجة في معدل النقل.
الأدوات والمكتبات: توفر العديد من اللغات والأنظمة البيئية مكتبات لتوليد المعرفات الفريدة. في Python، يمكن استخدام حزم لـ Snowflake أو UUID (وحدة uuid في Python). تستخدم قواعد بيانات مثل MongoDB معرف ObjectID مكون من 12 بايت (يشمل طابعًا زمنيًا، معرف الجهاز، وعداد) – وهو نهج مشابه لـ Snowflake لكنه مشفر بشكل مختلف. هذا نموذج آخر: معرفات ObjectID فريدة عالميًا وقابلة للترتيب حسب الوقت. يمكن لـ ERP تبني معرفات على نمط Mongo حتى لو لم تستخدم MongoDB. أيضًا، يُنصح باستخدام بادئات زمنية لتسلسلات قابلة للقراءة من قبل الإنسان (مثلاً أرقام الفواتير غالبًا ما تتضمن السنة أو التاريخ). هذا يقلل من نطاق التصادم ويعطي ترتيبًا ضمنيًا. مثلاً، الفاتورة "2025-INV-000001" – الجزء "2025" يعني تسلسلًا جديدًا كل سنة. يمكن بدء كل سنة بأمان من 1 دون تعارض مع السنوات السابقة، وإذا كانت هناك خوادم إقليمية تولد الفواتير، طالما تضمنت رمز المنطقة أو نطاقًا مختلفًا، فلن تتصادم.
الملخص: تحقيق التفرد العالمي والترتيب يتطلب إما تنسيقًا أو ترميزًا ذكيًا. الحلول الأكثر قابلية للتوسع (Snowflake، ObjectID، UUID) تتجنب الأقفال المركزية وتدمج معلومات كافية في المعرف لجعل التصادمات شبه مستحيلة. نوصي باستخدام خدمة شبيهة بـ Snowflake لنظام ERP لتوليد المفاتيح الأساسية (خصوصًا لأشياء مثل InvoiceID حيث يتطلب العمل تفردًا). هذا يمنحك معرفات 64-بت مرتبة زمنيًا يمكنها التوسع إلى أحجام ضخمة[11]. استخدم UUIDs حيث لا يكون الترتيب مهمًا ولكن تحتاج إلى رمز فريد سريع (معرفات الجلسات، مفاتيح عشوائية). وللأشياء التي تحتاج تسلسلات سهلة القراءة من قبل الإنسان، نفذها لكل نطاق (مثلًا لكل شركة أو سنة) أو استخدم منسقًا مركزيًا صغيرًا مع تخصيص نطاقات. الطرق الموضحة (والتي تستخدم في Twitter/Instagram/إلخ) ستضمن لنظام ERP الخاص بك تجنب مشاكل مؤلمة مثل أرقام الفواتير المكررة أو العدادات غير المتناسقة حتى عند التشغيل عبر العديد من الخوادم.
6. المصادقة والتفويض
معالجة مصادقة المستخدم وتفويضه في نظام موزع جغرافيًا وعلى نطاق واسع يتطلب نهجًا مركزيًا آمنًا مع بقاء زمن الاستجابة منخفضًا للمستخدمين في جميع أنحاء العالم. التحديات الرئيسية تشمل مزامنة بيانات المصادقة، تجنب تسجيلات الدخول المتعددة إذا انتقل المستخدم بين مناطق، وإدارة الجلسات أو الرموز عبر خوادم موزعة.
إدارة الهوية المركزية: عادةً ما تمتلك المنصات الكبيرة خدمة مصادقة مركزية أو قاعدة بيانات مستخدمين تُعد مصدر الحقيقة للاعتمادات والصلاحيات. على سبيل المثال، عند تسجيل الدخول إلى Facebook أو LinkedIn، يتم التحقق من بيانات الاعتماد مقابل مخزن مستخدمين مركزي. في إعداد متعدد المناطق، هذا لا يعني بالضرورة قاعدة بيانات مادية واحدة – يمكن تكرار قاعدة بيانات المستخدمين عالميًا، لكنها منطقياً نظام واحد (مع معرفات مستخدم فريدة عبر المنصة بأكملها). يجب أن يستخدم ERP دليل مستخدم موحدًا مشابهًا (مثلاً PostgreSQL مركزي أو LDAP للمستخدمين/الأدوار) يمكن الوصول إليه من جميع المناطق. لتحقيق زمن استجابة منخفض، أحد الأساليب هو مزامنة بيانات المصادقة إلى كل منطقة (أو على الأقل ذاكرة تخزين مؤقتة مشفرة لهاش كلمات المرور، إلخ)، بحيث لا يتطلب تسجيل الدخول دائمًا استدعاءات عبر المحيط. استخدمت Facebook أنظمة مثل memcache أو ذاكرات تخزين مؤقت مملوكة لكل مركز بيانات لتخزين البيانات التي تُستخدم كثيرًا (جلسات المستخدم، الرموز)[1]. في الواقع، تقوم Instagram بتجميع خوادم التخزين المؤقت مع خوادم الويب في كل مركز بيانات لتجنب الكمون في عمليات القراءة[1]. للمصادقة، يمكن أن يحتفظ ذاكرة تخزين مؤقت للجلسات موزعة (مثلاً عنقود Redis) برموز الجلسات النشطة في الذاكرة في كل منطقة، محدثة عند تسجيل الدخول.
تسجيل الدخول بزمن استجابة منخفض: يتوقع المستخدمون ردود تسجيل دخول سريعة. لضمان ذلك في ERP موزع، قد يستخدم استراتيجية مثل المصادقة مرة واحدة، واستخدام الرموز بعد ذلك. عند تسجيل الدخول الأولي، إذا كانت خدمة المصادقة مركزية في منطقة المنزل مثلاً، قد يتم التحقق من بيانات المستخدم هناك. لكن بعد تسجيل الدخول بنجاح، يصدر النظام رمزًا موقعًا (JWT أو مشابه) للمستخدم. يمكن أن يكون هذا الرمز مستقلاً ذاتيًا (يشمل معرف المستخدم، الأدوار، انتهاء الصلاحية) وموقعًا من قبل السلطة المركزية. بعد ذلك، يمكن لأي خادم إقليمي التحقق من صحة الرمز محليًا (باستخدام مفتاح عام أو سري) بدون استعلام قاعدة بيانات، مما يحقق فحص مصادقة بزمن ثابت. هذا مشابه لكيفية عمل JWTs الخاصة بـ OAuth أو رموز API في العديد من الخدمات – تسمح بالتحقق اللامركزي. هذا يعني أيضًا أنه إذا سافر المستخدم أو خدمه مركز بيانات مختلف في الطلب التالي، فلن يحتاج إلى تسجيل الدخول مرة أخرى؛ الرمز صالح عالميًا. نقطة يجب الانتباه إليها: يمكن أن تكون عملية الإلغاء أو تسجيل الخروج صعبة مع الرموز عديمة الحالة (قد تحتاج إلى قائمة إلغاء أو فترة صلاحية قصيرة للرموز). بدلاً من ذلك، يمكن استخدام معرف جلسة مخزن في كوكي يرتبط بمخزن جلسة على الخادم (مثل مفتاح Redis). هذا يتطلب عمليات بحث، لكن إذا كان مخزن الجلسة مكررًا عالميًا (أو مقسمًا حسب المنطقة مع تكرار)، يمكن لأي منطقة جلب بيانات الجلسة. مثال حقيقي هو استخدام Instagram لـ Redis لتخزين الجلسات – حيث يمكن لأي خادم ويب استرجاع كائن جلسة المستخدم من Redis، مما يجعل تسجيل الدخول "يتبع" المستخدم[1].
تدفق المصادقة الإقليمية: تصميم آخر هو توجيه طلبات المصادقة إلى منطقة واحدة (مثل "خادم تسجيل دخول مركزي"). على سبيل المثال، قد يتم توجيه مستخدم يزور خادمًا في الاتحاد الأوروبي لتسجيل الدخول إلى خدمة المصادقة العالمية (ربما في الولايات المتحدة) التي تتحقق وتعيد رمزًا. هذا يضيف قليلًا من الكمون عند تسجيل الدخول لكنه نادر مقارنة بالتفاعلات الأخرى، وبمجرد إصدار الرمز لا تتحمل الطلبات التالية ذلك التكلفة. هذا النموذج يبسط الاتساق (مكان واحد فقط للتحقق من كلمات المرور) لكنه يتطلب اتصالًا عالميًا قويًا. تستخدم العديد من الأنظمة نهجًا مثل: API /login يخدم فقط من خلال عنقود مركزي (أو خدمة ميكرو عالمية)، بينما تُخدم APIs الأخرى إقليميًا مع مصادقة بالرموز.
تسجيل الدخول الموحد (SSO) والاتحاد: في سيناريوهات المؤسسات، قد يتم مصادقة المستخدمين عبر SSO (مثل التكامل مع مزود هوية مثل Active Directory أو Okta، إلخ). في نظام ERP متعدد المناطق، يقوم التطبيق بإعادة التوجيه إلى جهة SSO المركزية لتسجيل الدخول، ثم يحصل على رمز SAML أو OAuth يتم قبوله عبر المنصة بأكملها. الميزة هي أنه يستفيد من دليل مركزي موجود ويمكن دمج المصادقة متعددة العوامل (MFA) وغيرها. كما أنه ينتج رمزًا صالحًا في أي مكان. العيب قد يكون التعقيد والاعتماد على أنظمة خارجية، ولكن من الجدير بالذكر إذا كان ERP مخصصًا لمنظمات كبيرة، فإن دعم SSO أمر أساسي.
التفويض (الأذونات): بجانب المصادقة، فإن ضمان التفويض الصحيح أمر حيوي خاصة مع نمو النظام (من يمكنه الموافقة على فاتورة، ومن يمكنه الوصول إلى بيانات معينة). عادةً ما يتم تنفيذ نظام التحكم في الوصول بناءً على الدور (RBAC)، وغالبًا ما يكون مركزيًا أيضًا. على سبيل المثال، قد يتم تخزين أدوار المستخدم أو عضوياته في مجموعات في قاعدة بيانات المصادقة المركزية ويتم تضمينها في الرمز أو يمكن استرجاعها عند الطلب. على نطاق واسع، يجب أيضًا تخزين الأذونات مؤقتًا – مثلاً، إذا كانت أدوار المستخدم موجودة في JWT، يمكن لكل خدمة فرض الأذونات بناءً على هذه الادعاءات دون الحاجة لاستعلام قاعدة البيانات. إذا كانت أكثر ديناميكية، يمكن لخدمة مثل Amazon Cognito أو Azure AD إدارة المصادقة الموزعة، لكن يمكن أيضًا بناء خدمات أذونات خفيفة مخصصة.
تقنيات إدارة الجلسة: كما ذُكر، استخدام الرموز عديمة الحالة (مثل JWT) هو خيار شائع لإدارة الجلسات الموزعة. هذا يدفع الحالة إلى العميل ويتجنب تخزين الجلسة على الخادم تمامًا (باستثناء ربما قائمة سوداء مركزية للرموز عند تسجيل الخروج). تقنية أخرى هي الجلسات اللاصقة على المستوى العالمي – لكنها تصبح معقدة. على سبيل المثال، يمكنك تثبيت المستخدم ليصل دائمًا إلى خوادم منطقته الأصلية طوال مدة جلسته لتجنب مشاكل عبر المناطق (قام LinkedIn بتثبيت المستخدمين على مركز بيانات[2]). هذا يضمن أن كل تفاعلات المستخدم (في تلك الجلسة) تذهب إلى قاعدة بيانات إقليمية واحدة (مما يقلل من نزاعات قواعد البيانات متعددة الماستر). الجانب السلبي هو أنه إذا سافر المستخدم أو تعطل ذلك المركز، ستحتاج إلى استراتيجية إعادة تثبيت. من الأسهل لنظام ERP استخدام نهج الرموز والسماح لأي منطقة بخدمة المستخدم، مع الاعتماد على كون البيانات الموزعة متناسقة أو استخدام بحث عالمي لأي معلومات مفقودة.
الحماية من تهديدات المصادقة: تتضمن الأنظمة الكبيرة أيضًا تدابير مثل تحديد معدل محاولات تسجيل الدخول، واستخدام CAPTCHA أو MFA لمحاولات تسجيل الدخول المشبوهة، وتجزئة وتتبيل كلمات المرور بأمان (مثلاً باستخدام bcrypt أو Argon2). يجب تطبيق هذه كلها في ERP. من الأفضل تخزين كلمات المرور في خزنة آمنة واحدة (ومزامنة قاعدة بيانات التجزئة للقراءة فقط حسب الحاجة) بدلاً من وجود مخازن مستخدمين متعددة متباينة.
مثال – مصادقة Instagram: رغم أن التفاصيل ليست علنية حول مصادقة Instagram، نعلم أن Instagram (كجزء من Facebook) يسمح باستخدام حسابات Facebook لتسجيل الدخول أيضًا. في سياق البنية: تشير واجهات Instagram عديمة الحالة واستخدام Redis للجلسات إلى أنهم يصدرون كوكي جلسة يتم التعرف عليه من قبل جميع خوادم الويب[1]. إذا وصل طلب المستخدم إلى خادم مختلف، يمكنه جلب معلومات الجلسة من Redis عبر معرف الجلسة ومصادقة المستخدم. هذا في الواقع نهج مخزن جلسة موزع.
مثال – مقياس LinkedIn: كان على LinkedIn التعامل مع مئات الملايين من المستخدمين الذين يقومون بتسجيل الدخول. بعد الانتقال إلى الميكروسيرفيسز، من المحتمل أنهم يستخدمون خدمة مركزية لمعالجة بيانات الاعتماد. كما نفذوا أنظمة مثل Galene للأهمية وربما استخدموها للتحقق من الأذونات السياقية (مع أن Galene كانت أكثر لترتيب الخلاصات). رغم أن بنية المصادقة المحددة غير مفصلة في مصادرنا، يمكننا الاستنتاج أن أشياء مثل 100 مليار استدعاء REST يوميًا[2] كان يجب مصادقتها جميعًا. هذا الحجم يشير إلى أن الحمل على كل استدعاء يجب أن يكون ضئيلاً (من المحتمل أن يكون مصادقة قائمة على الرموز مع تحقق خفيف الوزن).
التفويض الموزع: تحدي آخر هو إذا كانت بعض الإجراءات تحتاج إلى تنسيق – مثلاً، توليد رقم فاتورة متسلسل فريد عالميًا في الوقت الفعلي قد يتطلب التحقق من تسلسل مركزي (مرتبط بالتحكم في التزامن). لكن بالنسبة لعمليات القراءة والكتابة العامة، يمكن لكل خدمة فرض الأذونات على نطاق بياناتها طالما أن أدوار/ادعاءات المستخدم معروفة.
الحفاظ على توفر عالي للمصادقة: يجب أن يكون نظام المصادقة نفسه عالي التوفر – نسخ متعددة من قاعدة بيانات المستخدمين، نسخ متعددة من خدمة إصدار الرموز، إلخ. إذا كنت تستخدم JWTs، سيكون لديك مفتاح (أو زوج مفاتيح) للتوقيع؛ إدارة هذه المفاتيح بعناية (تدوير، توزيع المفتاح العام على كل الخدمات). من أفضل الممارسات هو استخدام مصادقة عديمة الحالة لتقليل الاعتماد على الأنظمة المركزية – بمجرد مصادقة المستخدم، حتى لو تعطلت قاعدة بيانات المصادقة المركزية، تظل الرموز الحالية صالحة حتى انتهاء صلاحيتها، مما يسمح للنظام بالاستمرار في العمل للمستخدمين المسجلين.
في الختام، لنظام ERP قابل للتوسع: قم بمركزية المصادقة لكن وزع التحقق. استخدم مصدرًا واحدًا لبيانات اعتماد وهوية المستخدم (ضمان أن اسم المستخدم الواحد = مستخدم واحد عالميًا)، ولكن بعد تسجيل الدخول، اعتمد على رموز آمنة أو مخازن جلسات موزعة بحيث يمكن لأي خادم في أي منطقة مصادقة الطلبات بدون تواصل ثقيل عبر المناطق. هذا يوفر نظام مصادقة منخفض الكمون وقابل للتوسع. نفذ أيضًا ممارسات أمان قوية (تشفير، تجزئة، دعم MFA) لأنه على نطاق واسع، ستكون المصادقة هدفًا رئيسيًا للهجمات.
7. أنظمة الإشعارات والرسائل
ترسل المنصات الكبيرة أعدادًا هائلة من الإشعارات وتتولى التعامل مع الرسائل الفورية بين المستخدمين. بالنسبة لنظام ERP، قد تشمل أنظمة الإشعارات البريد الإلكتروني (الفواتير، التذكيرات)، تنبيهات الرسائل القصيرة، الإشعارات الفورية، والرسائل أو التحديثات داخل التطبيق (مثل تحديث لوحة التحكم عند وصول بيانات جديدة). لتحقيق هذا بشكل موثوق لملايين الأحداث، يتطلب الأمر فك الترابط عبر بنية رسائل متخصصة.
المعالجة غير المتزامنة للإشعارات: من المواضيع الشائعة استخدام قوائم الرسائل والعمال الخلفيين لإرسال الإشعارات. بدلاً من إرسال بريد إلكتروني أو رسالة نصية مباشرة أثناء طلب المستخدم، يقوم النظام بإدخال مهمة إشعار في قائمة انتظار لتُعالج بواسطة خوادم العاملين. بهذه الطريقة، لا تتباطأ الإجراءات التي يواجهها المستخدم بسبب بوابات البريد الإلكتروني الخارجية أو خدمات الإشعارات الفورية. توضح مناقشة في Reddit حول توسيع الإشعارات بإيجاز: “تستخدم المراسلة غير المتزامنة. تدفع الإشعار إلى قائمة انتظار ثم يستهلك العمال هذه الرسائل لإجراء مهمة إرسال الإشعارات… يمكن إصلاح تقريبًا كل مشكلة توسعية للمشاكل غير الفورية من خلال قوائم الانتظار وتوسيع العمال”[12][12]. يتبع Instagram هذا النموذج: يستخدم RabbitMQ مع عمال Celery للتعامل مع مهام مثل إرسال الإشعارات، وتحديثات التوزيع، والمهام الخلفية الأخرى[1]. عند قيام مستخدم بفعل يسبب إشعارات (مثل موافقة على أمر شراء ترسل بريدًا إلكترونيًا للمديرين المعنيين)، يرسل خادم الويب رسالة إلى قائمة انتظار مثل “إرسال البريد الإلكتروني X إلى المستخدم Y” ويعود فورًا إلى العمل الآخر. ستقوم مجموعة من عمليات عامل الإشعارات المخصصة بسحب الرسالة وتنفيذ الإرسال الفعلي (عبر خادم SMTP أو API طرف ثالث). يسمح هذا بتوسيع معدل النقل بمجرد إضافة المزيد من عمليات العمال مع زيادة حجم الإشعارات، كما وصف CTO في Reddit (مراقبة طول قائمة الانتظار وإضافة العمال حسب الحاجة)[12].
البريد الإلكتروني والرسائل القصيرة على نطاق واسع: بالنسبة للبريد الإلكتروني، يمكن الدمج مع خدمات مثل Amazon SES، SendGrid، أو تشغيل مجموعة من خوادم البريد. على نطاق واسع، تأكد من التعامل مع الارتدادات والحد من الإرسال. بالنسبة للرسائل القصيرة، من الشائع الدمج مع مزودي خدمات مثل Twilio أو بوابات شركات الاتصالات مباشرة. تكون هذه التفاعلات الخارجية محدودة المعدل، لذا يساعد نظام قوائم الانتظار على تنعيم فترات الذروة. يجب معالجة الإشعارات الجماعية (مثل كشوف نهاية الشهر لجميع العملاء) في دفعات عبر العمال لتجنب الرسائل المزعجة أو تحميل مزود أو IP واحد بشكل زائد – وهذا أيضًا ما يتعامل معه تصميم قائمة الانتظار + العمال بالتحكم في التزامن.
الإشعارات الفورية: إذا شمل ERP مكون تطبيق موبايل أو يستخدم الإشعارات عبر الويب، يتم إرسال الإشعارات الفورية عبر خدمات Apple APNs أو Google FCM. عادةً ما يتم بناء خدمة إشعارات فورية تقبل الأحداث الداخلية ثم تتواصل مع APNs/FCM. يمكن توسيع هذه الخدمة أفقياً. غالبًا ما تحافظ على تجمع اتصالات مع خوادم الإشعارات (APNs تستخدم HTTP/2 الآن؛ FCM له نقاط نهاية). تستخدم أنظمة الإشعارات عالية الحجم العديد من نسخ العمال للحفاظ على اتصالات متزامنة ومعدل نقل مرتفع. كما تتعامل مع ردود الفعل (مثل رموز الأجهزة غير صالحة، إلخ) وتحدث قاعدة البيانات وفقًا لذلك.
الرسائل الفورية داخل التطبيق: للميزات التي تتطلب تحديثات فورية (مثلاً، رمز جرس إشعارات يتحدث عند الحاجة لموافقة جديدة، أو دردشة مباشرة داخل ERP)، تُستخدم تقنيات مثل WebSockets، Server-Sent Events (SSE)، أو الاستطلاع الطويل. استخدم Facebook في البداية الاستطلاع الطويل (Comet) لتحقيق توصيل شبه فوري[4][4]. تنشئ اتصالات HTTP طويلة العمر وتدفع البيانات فور توفرها. تستخدم بنية Facebook Messenger مجموعة “خوادم القنوات” (مكتوبة بلغة Erlang) لإدارة الاتصالات الدائمة وقوائم الرسائل للدردشة الفورية[4][4]. تُعطى كل رسالة رقم تسلسلي وتُوضع في قائمة وتُسلم عبر هذه الخوادم التي صممت لتحمل عدد هائل من الاتصالات المتزامنة (تُستخدم Erlang لنموذج العمليات الخفيفة والقدرة على تحمل الأخطاء)[4]. قد لا يحتاج ERP إلى نظام دردشة كامل، لكنه قد يستفيد من خادم إشعارات قائم على WebSocket لدفع الأحداث فورًا (مثل ظهور نافذة “المخزون منخفض للمنتج XYZ”). يمكن لبايثون التعامل مع WebSockets (مثلاً عبر أُطر مثل Django Channels أو مكتبات مثل websockets/Tornado)، لكن قد يُنظر في خدمة متخصصة (حتى بلغة أخرى أو استخدام SaaS مثل Pusher) إذا توقعنا حجمًا ضخمًا.
تدفق الأحداث (داخلي): داخل الباكند، تستخدم منصات تدفق الأحداث عالية الحجم مثل Apache Kafka لنقل البيانات بين الخدمات في وقت شبه حقيقي. أنشأ LinkedIn Kafka لتوحيد خطوط الأنابيب للأحداث مثل تتبع مشاهدات الصفحات، تحديث فهارس البحث عند تغيير الملفات الشخصية، تسليم InMail، إلخ[2][2]. Kafka هو سجل نشر-اشتراك موزع حيث يكتب المنتجون الأحداث ويمكن للعديد من المستهلكين قراءتها. في سياق ERP، يمكن استخدام Kafka (أو أنظمة مشابهة مثل RabbitMQ، AWS Kinesis، Google Pub/Sub) لبث أحداث مثل “InvoiceCreated” أو “StockLevelChanged” لأي خدمة مهتمة. مثلاً، عند دفع فاتورة (حدث في وحدة المالية)، قد تستهلك خدمة المخزون ذلك الحدث لتحرير المخزون المحجوز، وتستهلك خدمة CRM لتحديث تاريخ شراء العميل، وترسل خدمة الإشعارات بريدًا إلكترونيًا للتأكيد – كل ذلك بشكل غير متزامن ومفكك عبر حافلة الأحداث. تشتهر Kafka بقدرتها على التعامل مع ملايين الأحداث في الثانية؛ أفاد LinkedIn أن Kafka كانت تتعامل مع أكثر من 500 مليار حدث يوميًا منتصف 2015[2]. يُظهر هذا الحجم موثوقية فك الترابط عبر السجلات – يمكنك إضافة المزيد من المستهلكين دون التأثير على المنتجين. للحل القائم على بايثون، يمكن استخدام Kafka مع عميل بايثون (مثل confluent-kafka)، أو RabbitMQ لاحتياجات قوائم الانتظار الأبسط. يُستخدم RabbitMQ غالبًا لقوائم المهام (كما في Instagram Celery) بينما يتألق Kafka في سيناريوهات النشر والاشتراك عالية الإنتاجية والبث.
التوزيع الجماعي وضمانات التسليم: عندما يؤدي فعل واحد إلى إشعارات عديدة (توزيع جماعي)، يكون وسيط الرسائل مفيدًا لتوزيع عبء العمل. مثلاً، يوافق مدير على طلب ويجب إعلام 50 شخصًا – بدلاً من أن يكرر خادم التطبيق إرسال 50 رسالة، يمكنه نشر حدث واحد يتعامل معه 50 مستهلكًا (أو مستهلكًا يقوم بإنشاء 50 مهمة). تضمن أنظمة مثل Kafka وRabbitMQ دوام الرسائل (حتى لا تضيع حتى لو أعيد تشغيل الخدمة، طالما تم تكوينها مع الاستمرارية والتكرار). هذا أمر حاسم للنزاهة – إذا أرسلت 1000 بريد إلكتروني للعملاء، تريد التأكد من أنهم سيصلون في النهاية حتى لو حدث تعطل. صمم نظام الإشعارات مع تسليم على الأقل مرة واحدة (مسموح أن يتم إرسال البريد نادرًا مرتين، لكن غير مقبول أن يُفقد – لذا عالج التكرار على جانب المستهلك عبر التحقق من سجل الإرسال إذا لزم الأمر).
تحديثات لوحة التحكم في الوقت الحقيقي: بالإضافة إلى رسائل المستخدم، قد يحتوي نظام (ERP) على لوحات تحكم في الوقت الحقيقي يتم تحديثها عند ورود بيانات جديدة (مثلاً، تحديث المخطط البياني للمبيعات عند وصول طلبات جديدة). يمكن تنفيذ هذا باستخدام (WebSockets) أو (SSE) لدفع التحديثات إلى عملاء المتصفح. وهناك نهج آخر وهو الاستطلاع عبر AJAX بفواصل زمنية، وهو أبسط لكنه أقل كفاءة عند التوسع. النهج الحديث هو أن يقوم العميل بالاشتراك في التحديثات (قد يكون عبر (WebSocket) أو حتى اشتراكات (GraphQL)) ويقوم الخادم بدفع الفروقات. خلف الكواليس، يمكن ربط ذلك بنفس نظام الأحداث – مثلاً، عند إنشاء طلب جديد، يتم تشغيل حدث لا يؤثر فقط على العمليات الخلفية بل يُرسل أيضاً إلى خادم (WebSocket) الذي يقوم بإخطار جميع لوحات تحكم الإدارة المتصلة.
البنية التحتية للرسائل: "الأنابيب" تشمل التأكد من وجود وسطاء/خوادم معدة مسبقاً: مثلاً، عنقود (Kafka) (مع وسطاء متعددين) إذا كان مطلوباً للتوسع، أو عنقود (RabbitMQ) (يمكن تكوين (RabbitMQ) في عنقود لزيادة التوفر (HA)). وأيضاً، (Redis) يستخدم أحياناً كنظام نشر/اشتراك خفيف الوزن أو تدفق بيانات (ميزة (Redis Streams)) للحالات الأبسط. لدى (Facebook) نظام نشر/اشتراك داخلي يسمى (Wormhole) لنشر تغييرات البيانات عبر الأنظمة ومراكز البيانات في الوقت الحقيقي[7][7]. يساعد (Wormhole) بشكل خاص على إبقاء الذاكرات المؤقتة (الكاش) متزامنة ومؤشرات البحث محدثة من خلال إرسال رسائل إبطال الكاش وتحديثاته كلما تغيرت بيانات المستخدم[7][7]. يعالج أكثر من 1 تريليون رسالة يومياً على تدفقات بيانات قاعدة مستخدميه[7]. وهذا يبرز أن الرسائل الداخلية ليست فقط لميزات المستخدمين بل أيضاً للحفاظ على الاتساق والكفاءة خلف الكواليس. بالنسبة لنظام (ERP) الخاص بنا، يمكن أن يكون ما يعادل ذلك مصغر هو إرسال أحداث إبطال الكاش لجميع خوادم التطبيق عند تحديث بيانات معينة، ليتمكنوا من إبطال أي كاش محلي – لضمان أن يرى المستخدمون بيانات جديدة بسرعة على مستوى العالم (وهذا النهج يمكن تحقيقه أيضاً باستخدام أدوات مثل (Redis) أو (Hazelcast) لتناسق الكاش الموزع).
مراقبة وإدارة أنظمة الإشعارات: عند التوسع، تحتاج أيضاً إلى مراقبة قوائم الانتظار – عدد الرسائل المعلقة، معدلات المعالجة، الأخطاء. إذا توقفت خدمة البريد الإلكتروني وتكدست الرسائل، يجب أن يتم تنبيه فريق التشغيل. نفذ إعادة المحاولة مع تراجع تدريجي للإرسال الخارجي (إذا فشل إرسال البريد الإلكتروني، يعاد المحاولة عدة مرات، ثم قد يتم التوقف وتسجيل خطأ لتدخل يدوي). استخدم قوائم الرسائل الميتة (DLQs - Dead Letter Queues) للرسائل التي تفشل باستمرار في المعالجة، حتى لا تعطل قائمة الانتظار الرئيسية.
باختصار، الاستراتيجية هي: فصل الإشعارات والرسائل عن التدفق الرئيسي باستخدام القوائم وأنظمة النشر/الاشتراك. استخدم عمال الخلفية للتعامل مع حجم الإرسال العالي (كما يفعل (Instagram) باستخدام (RabbitMQ/Celery))[1]، واستخدم قنوات الدفع الفوري (مثل (WebSocket)/(SSE)) لتحديثات فورية للمستخدمين عند الحاجة، مدعومة ربما بخدمة متخصصة مثل خوادم القنوات الخاصة بفيسبوك للدردشة[4][4]. اعتماد تقنيات مثبتة مثل (Kafka) لبث الأحداث و(RabbitMQ) لتوزيع المهام سيسمح لنظام (ERP) بتوصيل آلاف أو ملايين الإشعارات يومياً، وتحديث المستخدمين في الوقت الحقيقي، كل ذلك مع الحفاظ على استجابة النظام الأساسي.
٨. إرشادات التطبيق العملي
دمج هذه الاستراتيجيات معًا، إليك أفضل الممارسات ومبادئ التصميم لبناء نظام (ERP) قائم على بايثون يكون قابلًا للتوسع، ومتسقًا، وعالي التوفر، مع توجيهات ملموسة مستمدة من نجاحات فيسبوك، ولينكدإن، وإنستغرام، وغيرهم:
- تصميم معياري موجه بالخدمات: صمم نظام (ERP) كمجموعة من الخدمات أو الوحدات (المحاسبة، المخزون، إدارة علاقات العملاء، إلخ) بدلاً من برنامج ضخم واحد. هذا يتبع فلسفة الخدمات المصغرة المستخدمة في (لينكدإن) و(فيسبوك)[3]. يمكن لكل وحدة أن تمتلك مخزن بيانات خاص بها ويمكن توسيعها أو تحديثها بشكل مستقل. حدد واجهات برمجة التطبيقات (APIs) بوضوح بين الوحدات. ابدأ بنظام أحادي معياري إذا لزم الأمر (للبساطة)، لكن مع فصل منطقي يمكن تفكيكه لاحقًا.
- طبقة التطبيق عديمة الحالة (Stateless): صمم خوادم الويب/التطبيقات لتكون عديمة الحالة وقابلة للتوسع أفقيًا. استخدم أُطُر عمل مثل (Django) كما فعل (إنستغرام)[1] أو (Flask/FastAPI) لبايثون، لكن تجنب تخزين بيانات المستخدم الخاصة على القرص المحلي أو الذاكرة. استخرج حالة الجلسة خارجيًا (استخدم (Redis) أو الرموز (tokens)) وتخزين الملفات (استخدم نظام ملفات موزع أو تخزين سحابي). يسمح هذا بتشغيل عدة خوادم تطبيق خلف موازنات التحميل، وتنفيذ تحديثات دورية بدون توقف. خدمات لينكدإن العديمة الحالة واستخدامهم لموازنات التحميل سمحت لهم بـ التوسع فقط بإضافة نسخ جديدة[2].
- استخدام التخزين المؤقت بحكمة: أدخل التخزين المؤقت على مستويات متعددة لتقليل حمل قاعدة البيانات وتحسين أوقات الاستجابة. نفذ طبقة تخزين مؤقت في الذاكرة (مثل (Redis) أو (Memcached)) للقراءات المتكررة، كما تفعل الشركات الثلاث (فيسبوك باستخدام (memcache)[3]، إنستغرام باستخدام (memcache/Redis)[1]، لينكدإن باستخدام (Voldemort/Memcached)[2]). مع ذلك، صمم إبطال التخزين المؤقت بعناية للحفاظ على الاتساق (فكر في استخدام نظام نشر/اشتراك مثل (Wormhole) الخاص بفيسبوك لإبطال الكاش عبر النسخ بسرعة[7][7]). يجب أن تحتوي البيانات المخزنة مؤقتًا على (TTL) مناسب أو تُمسح صراحةً عند التحديثات. استهدف تخزين البيانات التي تُقرأ بكثرة ولا تتغير كثيرًا (مثل جداول المراجع، ملفات المستخدمين)، لكن كن حذرًا مع البيانات الديناميكية بشكل كبير.
- هيكلية قاعدة بيانات قوية: استخدم قاعدة بيانات علائقية كمصدر أساسي للحقائق لضمان سلامة المعاملات (مثل (PostgreSQL) أو (MySQL)). نفذ استنساخ رئيسي-نسخة (master-replica replication) لتوسيع عمليات القراءة وضمان التوفر العالي (كان لدى قاعدة بيانات إنستغرام 12 نسخة[1]؛ لينكدإن يستخدم نسخًا متعددة وفي النهاية التقسيم[2]). خطط استراتيجية تقسيم (sharding) مبكرًا – حتى إذا بدأت بقاعدة بيانات واحدة، صمم المخطط والكود لاستيعاب التقسيم حسب المفتاح (مثل المستخدم أو الشركة). فكر في استخدام التقسيم المبني على المخطط (كما تفعل إنستغرام)[5] أو التقسيم على مستوى التطبيق عبر طبقة وصول البيانات. بالنسبة للنشر العالمي، قرر بين قاعدة بيانات عالمية واحدة (مع احتمال تأخير) مقابل قواعد بيانات إقليمية متعددة (مع الاتساق النهائي). يختار الكثيرون منطقة رئيسية واحدة للكتابة ونسخ قراءة في المناطق الأخرى لتحقيق توازن في المقايضة.
- ضمان القيود الفريدة وتجنب التكرار: لمنع الإدخالات المكررة (مثل أرقام الفواتير أو معرفات المستخدمين)، نفذ طريقة موثوقة لتوليد معرفات فريدة. يُوصى باستخدام مولد معرف موزع (مثل (Snowflake)) للتوسع، كما ذُكر سابقًا[11]. هذا يمنع التصادمات دون عنق زجاجة مركزية. بالإضافة لذلك، طبق قيود قاعدة البيانات (فهارس فريدة على رقم الفاتورة، إلخ) كشبكة أمان – إذا حاول مدخلان استخدام نفس المعرف، سترفض قاعدة البيانات أحدهما. استخدم المعاملات عند إنشاء هذه السجلات، حتى تحل قاعدة البيانات أي حالة تعارض (نجاح واحد، الآخر يعيد المحاولة بمعرف جديد). في الحالات التي تتطلب ترقيمًا متسلسلًا صارمًا (عادة في عمليات التدقيق حيث لا يجوز وجود فجوات في أرقام الفواتير)، قد تحتفظ بخدمة صغيرة أو تسلسل قاعدة بيانات مخصصة وتديرها بحذر (ربما موزعة حسب المنطقة أو السنة). المفتاح هو أن كل مسار لإنشاء فاتورة جديدة يمر عبر مخصص واحد (سواء كان خوارزمية أو خدمة)، لذا يتم تجنب التكرارات بطبيعتها.
- إعداد التوفر العالي: انشر نظام (ERP) على الأقل في مركز بيانات رئيسي وثانوي، أو في مناطق توفر متعددة إذا كان على السحابة، لتحمل الأعطال. استخدم موازنات تحميل مع فحوصات الصحة لإزالة العقد المعطلة تلقائيًا[2]. قم بإعداد تبديل قاعدة البيانات في حالة الفشل (مثل (MySQL) مع ترقية تلقائية للنسخ، أو استخدم قواعد بيانات مدارة سحابياً تتعامل مع التبديل). نفذ نسخ احتياطية مستمرة وربما تكرار جغرافي للبيانات (يقوم فيسبوك بالتكرار متعدد مراكز البيانات للتعافي من الكوارث[3]). مارس تدريبات التعافي من الكوارث – مثلاً، حاكي توقف قاعدة البيانات الرئيسية وتأكد من أن الثانوية تستطيع تولي المهمة دون فقدان بيانات (تتعامل استراتيجية النسخ الاحتياطي في فيسبوك مع أحجام ضخمة للحفاظ على الأداء[3]).
- الانخفاض التدريجي والاختبار: أدرج مفاتيح تفعيل/تعطيل الميزات لإيقاف الميزات غير الحرجة إذا كان النظام تحت ضغط شديد. مثلاً، قد تعطّل توليد تقارير PDF خلال ساعات الذروة إذا كانت ترهق النظام، مع إعلام المستخدمين، مع الحفاظ على تشغيل العمليات الأساسية. اختبر النظام تحت الحمل (قم باختبار تحميل حتى 10 أضعاف الحمل المتوقع لرصد نقاط الاختناق[12]) وتحت الفشل (استخدم مبادئ اختبار الفوضى: قتل نسخ، قطع الاتصالات الشبكية لضمان أن النظام يتعامل مع ذلك بسلاسة).
- الأمان والمصادقة على نطاق واسع: نفذ مصادقة آمنة باستخدام ممارسات حديثة (التجزئة، التمليح، (TLS) في كل مكان). استخدم مصادقة مركزية وأصدر رموز (tokens) لتمكين التوسع (كما هو مذكور، مصادقة الرموز تتجنب ضغوط قاعدة البيانات عند كل طلب). إذا كنت تستخدم (JWTs)، ضمن الأدوار/الأذونات اللازمة للمستخدم فيها للتحقق السريع من التفويض. راجع منطق الأذونات بانتظام لتجنب تصعيد الامتيازات خاصةً عند وجود خدمات متعددة (يمكن أن يساعد النهج ذو الثقة الصفرية داخليًا: كل خدمة تتحقق من الأذونات حتى لو كانت خدمة أخرى تناديها). راقب أحداث المصادقة لمنع الإساءة (حدد معدل محاولات الدخول لكل عنوان IP لمنع الهجمات بالقوة العنيفة).
- الاستفادة من نقاط قوة بايثون ومعالجة نقاط ضعفها: تتيح بايثون تطويرًا سريعًا (كما في حالة إنستغرام باستخدام (Django) لبناء الميزات بسرعة[1]) ولها نظام بيئي غني (مثل (Celery) لقائمة المهام، (NumPy/Pandas) للتحليلات، إلخ). لكن أداء بايثون في الخيوط المفردة محدود بسبب (GIL). للتوسع في المهام الحسابية المكثفة، استخدم تعدد المعالجات أو نفّذها في عمليات عمالية منفصلة – وهذا يتماشى مع البنية الموزعة على أي حال. استخدم أُطُر العمل غير المتزامنة (asyncio، FastAPI) للمهام المعتمدة على الإدخال/الإخراج للتعامل مع المزيد من الطلبات المتزامنة مع عدد أقل من الخيوط، إذا لزم الأمر. فكر أيضًا في دمج لغات أكثر ملاءمة لبعض المهام (مثلاً استخدام مكتبة (C) للعمليات العددية الثقيلة، أو استخدام (Node/Go) لخدمة (WebSocket) متخصصة) – العديد من الأنظمة الكبيرة متعددة اللغات (لينكدإن أساسًا جافا، بعض (Node)، ويتواصلون عبر (REST/Thrift APIs)[2]).
- التسجيل، المراقبة، والتحليلات: قم ببناء تسجيل شامل في نظام (ERP) منذ اليوم الأول. استخدم مجموعة (ELK) أو تسجيل السحابة لتجميع السجلات. يجب جمع مقاييس (qps، الكمون، معدلات الخطأ، حمل قاعدة البيانات، أطوال قوائم الانتظار) – كما تتعقب إنستغرام المقاييس باستخدام (StatsD) والعدادات الداخلية للتسجيلات، الإعجابات، إلخ[1]. هذا يساعد في ضبط الأداء واكتشاف المشاكل مبكرًا. مع نمو البيانات، خطط للتحليلات – ربما تصدير البيانات دوريًا إلى مستودع بيانات (كما تفعل إنستغرام بالأرشفة إلى (Hive)[1]) حتى لا تثقل تقارير الأداء النظام الحي.
- التطور المستمر: توقع أن تتطور البنية على مدى سنوات. شملت رحلة لينكدإن عدة تحولات نموذجية (من النظام الأحادي إلى الخدمات المصغرة، إدخال (Kafka)، دعم مراكز بيانات متعددة)[2][2]. صمم مع وضع التغيير في الاعتبار: استخدم واجهات يمكن تبديلها (مثل طبقة وصول البيانات التي يمكن أن تتحول من قاعدة بيانات واحدة إلى قاعدة مقسمة أو إلى متجر (NewSQL) دون تغيير منطق العمل). راقب التقنيات الناشئة – على سبيل المثال قواعد بيانات (NewSQL) أو خدمات السحابة الأصلية قد تبسط بعض الجوانب مستقبلًا. مع ذلك، اعتمد على مكونات مثبتة (مشكلات التوسع غالبًا ما تنشأ من إعادة اختراع العجلة التي حلتها شركات مثل فيسبوك بالفعل).
- التوثيق والرسوم البيانية: كجزء من التطبيق العملي، حافظ على مخططات واضحة للبنية المعمارية وتوثيق (مماثل للتي تم الإشارة إليها هنا لإنستغرام ولينكدإن). هذا يساعد في تدريب أعضاء الفريق والتواصل حول التصميم. على سبيل المثال، أنشئ مخططات توضح كيف يتدفق طلب إنشاء فاتورة من المستخدم، مرورًا بموازنات التحميل، إلى خوادم التطبيق، ثم إلى قاعدة البيانات، ثم يشغل بريدًا إلكترونيًا في الخلفية عبر قائمة الانتظار. وجود هذه "النماذج الذهنية" مرسومة يضمن عدم التغاضي عن أي شيء ويساعد في استكشاف الأخطاء وإصلاحها.
باتباع هذه الممارسات الفضلى والتعلم من بنى الأنظمة في المنصات الكبرى، يمكن تصميم نظام (ERP) قائم على بايثون ليتمكن من التعامل مع ملايين المستخدمين، عبر نشرات هجينة بين السحابة والأنظمة المحلية، مع أداء موثوق ومساحة للتوسع. يجب أن يكون التركيز على قابلية التوسع (التوسع الأفقي، التخزين المؤقت، المعالجة غير المتزامنة)، والاتساق عند الحاجة (المعاملات، التقسيم الدقيق، المعرفات العالمية)، والمرونة (التكرار، التبديل التلقائي، المراقبة). كل قرار تصميم – من قاعدة البيانات إلى موازن التحميل إلى نظام الرسائل – يساهم في بناء نظام قادر على التعامل بسلاسة مع الأحمال العالية والنمو على المدى الطويل.
No comments yet. Login to start a new discussion Start a new discussion